
TOG (32), TVCG (45), SIGGRAPH/SA - Conference Track (6) | CHI/UIST/IMWUT/VR (17) | PAMI (4), CVPR/ICCV/ECCV/AAAI (18; Oral/Highlight: 6)
For the most updated list of publications, please check out my
Google Scholar page.
Feng-Lin Liu, Shi-Yang Li, Yan-Pei Cao, Hongbo Fu, and Lin Gao. Sketch3DVE: Sketch-based 3D-Aware Scene Video Editing. ACM SIGGRAPH 2025 Conference Papers. Article No. 152. December 2025. |
|
 |
Abstract: Recent video editing methods achieve attractive results in style transfer or appearance modification. However, editing the structural content of 3D scenes in videos remains challenging, particularly when dealing with significant viewpoint changes, such as large camera rotations or zooms. Key challenges include generating novel view content that remains consistent with the original video, preserving unedited regions, and translating sparse 2D inputs into realistic 3D video outputs. To address these issues, we propose Sketch3DVE, a sketch-based 3D-aware video editing method to enable detailed local manipulation of videos with significant viewpoint changes. To solve the challenge posed by sparse inputs, we employ image editing methods to generate edited results for the first frame, which are then propagated to the remaining frames of the video. We utilize sketching as an interaction tool for precise geometry control, while other mask-based image editing methods are also supported. To handle viewpoint changes, we perform a detailed analysis and manipulation of the 3D information in the video. Specifically, we utilize a dense stereo method to estimate a point cloud and the camera parameters of the input video. We then propose a point cloud editing approach that uses depth maps to represent the 3D geometry of newly edited components, aligning them effectively with the original 3D scene. To seamlessly merge the newly edited content with the original video while preserving the features of unedited regions, we introduce a 3D-aware mask propagation strategy and employ a video diffusion model to produce realistic edited videos. Extensive experiments demonstrate the superiority of Sketch3DVE in video editing.
|
Feng-Lin Liu, Hongbo Fu, Xintao Wang, Weicai Ye, Pengfei Wan, Di Zhang, and Lin Gao. SketchVideo: Sketch-based Video Generation and Editing. CVPR 2025. Nashville TN, USA. June 2025. |
|
 |
Abstract: Video generation and editing conditioned on text prompts or images have undergone significant advancements. However, challenges remain in accurately controlling global layout and geometry details solely by texts, and supporting motion control and local modification through images. In this paper, we aim to achieve sketch-based spatial and motion control for video generation and support fine-grained editing of real or synthetic videos. Based on the DiT video generation model, we propose a memory-efficient control structure with sketch control blocks that predict residual features of skipped DiT blocks. Sketches are drawn on one or two keyframes (at arbitrary time points) for easy interaction. To propagate such temporally sparse sketch conditions across all frames, we propose an inter-frame attention mechanism to analyze the relationship between the keyframes and each video frame. For sketch-based video editing, we design an additional video insertion module that maintains consistency between the newly edited content and the original video's spatial feature and dynamic motion. During inference, we use latent fusion for the accurate preservation of unedited regions. Extensive experiments demonstrate that our SketchVideo achieves superior performance in controllable video generation and editing. |
Dong Liang, Jinyuan Jia, Yuhao Liu, Zhanghan Ke, Hongbo Fu, and Rynson Lau. VODiff: Controlling Object Visibility Order in Text-to-Image Generation. CVPR 2025. Nashville TN, USA. June 2025. |
|
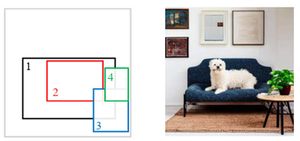 |
Abstract: Recent advancements in diffusion models have significantly enhanced the performance of text-to-image models in image synthesis. To enable control over the the spatial locations of the generated objects, diffusion-based methods typically utilize object layout as an auxiliary input. However, we observe that this approach treats all objects as being on the same layer and neglect their visibility order, leading to the synthesis of overlapping objects with incorrect occlusions. To address this limitation, we introduce in this paper a new training-free framework that considers object visibility order explicitly and allows users to place overlapping objects in a stack of layers. Our framework consists of two visibility-based designs. First, we propose a novel Sequential Denoising Process (SDP) to divide the whole image generation into multiple stages for different objects, each stage primarily focuses on an object. Second, we propose a novel Visibility-Order-Aware (VOA) Loss to transform the layout and occlusion constraints into an attention map optimization process to improve the accuracy of synthesizing object occlusions in complex scenes. By merging these two novel components, our framework, dubbed VODiff, enables the generation of photorealistic images that satisfy user-specified spatial constraints and object occlusion relationships. In addition, we introduce VOBench, a diverse benchmark dataset containing 200 curated samples, each with a reference image, text prompts, object visibility orders and layout maps. We conduct extensive evaluations on this dataset to demonstrate the superiority of our approach. |
Lin Gao, Jie Yang, Bo-Tao Zhang, Jia-Mu Sun, Yu-Jie Yuan, Hongbo Fu, and Yu-Kun Lai. Real-time
Large-scale Deformation for Gaussian Splatting. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH Asia 2024. 43(6). Article No. 200. December 2024. |
|
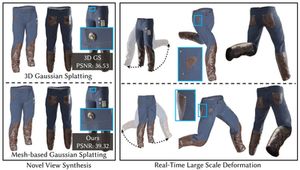 |
Abstract: Neural implicit representations, including Neural Distance Fields and Neural Radiance Fields, have demonstrated significant capabilities for reconstructing surfaces with complicated geometry and topology, and generating novel views of a scene. Nevertheless, it is challenging for users to directly deform or manipulate these implicit representations with large deformations in a real-time fashion. Gaussian Splatting (GS) has recently become a promising method with explicit geometry for representing static scenes and facilitating high-quality and real-time synthesis of novel views. However, it cannot be easily deformed due to the use of discrete Gaussians and the lack of explicit topology. To address this, we develop a novel GS-based method that enables interactive deformation. Our key idea is to design an innovative mesh-based GS representation, which is integrated into Gaussian learning and manipulation. 3D Gaussians are defined over an explicit mesh, and they are bound with each other: the rendering of 3D Gaussians guides the mesh face split for adaptive refinement, and the mesh face split directs the splitting of 3D Gaussians. Moreover, the explicit mesh constraints help regularize the Gaussian distribution, suppressing poor-quality Gaussians (e.g. , misaligned Gaussians, long-narrow shaped Gaussians), thus enhancing visual quality and reducing artifacts during deformation. Based on this representation, we further introduce a large-scale Gaussian deformation technique to enable deformable GS, which alters the parameters of 3D Gaussians according to the manipulation of the associated mesh. Our method benefits from existing mesh deformation datasets for more realistic data-driven Gaussian deformation. Extensive experiments show that our approach achieves highquality reconstruction and effective deformation, while maintaining the promising rendering results at a high frame rate (65 FPS on average on a single commodity GPU). |
Jie Zhou*, Chufeng Xiao*, Miu-Ling Lam, and Hongbo Fu. DrawingSpinUp: 3D Animation from Single Character Drawings. ACM SIGGRAPH Asia 2024 Conference Papers. Article No. 98. December 2024. |
|
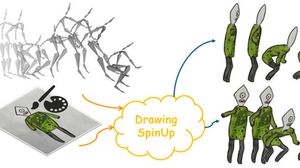 |
Abstract: Animating various character drawings is an engaging visual content creation task. Given a single character drawing, existing animation methods are limited to flat 2D motions and thus lack 3D effects. An alternative solution is to reconstruct a 3D model from a character drawing as a proxy and then retarget 3D motion data onto it. However, the existing image-to-3D methods could not work well for amateur character drawings in terms of appearance and geometry. We observe the contour lines, commonly existing in character drawings, would introduce significant ambiguity in texture synthesis due to their view-dependence. Additionally, thin regions represented by single-line contours are difficult to reconstruct (e.g., slim limbs of a stick figure) due to their delicate structures. To address these issues, we propose a novel system, DrawingSpinUp, to produce plausible 3D animations and breathe life into character drawings, allowing them to freely spin up, leap, and even perform a hip-hop dance. For appearance improvement, we adopt a removal-then-restoration strategy to first remove the view-dependent contour lines and then render them back after retargeting the reconstructed character. For geometry refinement, we develop a skeleton-based thinning deformation algorithm to refine the slim structures represented by the single-line contours. The experimental evaluations show that our method outperforms the existing 2D and 3D animation methods and generates high-quality 3D animations from single character drawings.
|
Zhiyi Kuang, Yanchao Yang, Siyan Dong, Jiayue Ma, Hongbo Fu, and Youyi Zheng. OLAT Gaussians for
Generic Relightable Appearance Acquisition. ACM SIGGRAPH Asia 2024 Conference Papers. Article No. 13. December 2024. |
|
 |
Abstract: One-light-at-a-time (OLAT) images sample a broader range of object appearance changes than images captured under constant lighting and are superior as input to object relighting. Although existing methods have produced reasonable relighting quality using OLAT images, they utilize surface-like representations, limiting their capacity to model volumetric objects, such as furs. Besides, their rendering process is time-consuming and still far from being used in real-time applications. To address these issues, we propose OLAT Gaussians to build relightable representations of objects from multi-view OLAT images. We build our pipeline on 3D Gaussian Splatting (3DGS), which achieves real-time high-quality rendering. To augment 3DGS with relighting capability, we assign each Gaussian a learnable feature vector, serving as an index to query the objects' appearance field. Specifically, we decompose the appearance field into an incident illumination function and a scattering function. The former accounts for light transmittance and fore-shortening effects, while the latter represents the object's material properties to scatter light. Rather than using an off-the-shelf physically-based parametric rendering formulation, we model both functions using multi-layer perceptrons (MLPs). This makes our method suitable for various objects, e.g., opaque surfaces, semi-transparent volumes, furs, fabrics, etc. Given a camera view and a point light position, we compute each Gaussian's color as the product of the light intensity, the incident illumination value, and the scattering value, and then render the target image through the 3DGS rasterizer. To enhance rendering quality, we further utilize a proxy mesh to provide OLAT Gaussians with normals to improve highlights and visibility cues to improve shadows. Extensive experiments demonstrate that our method produces state-of-the-art rendering quality with significantly more details in texture-rich areas than previous methods. Our method also achieves real-time rendering, allowing users to interactively modify camera views and point light positions to get immediate rendering results, which are not available from the offline rendering of previous methods.
|
Feng-Lin Liu, Hongbo Fu, Yun-Kun Lai, and Lin Gao. SketchDream: Sketch-based Text-to-3D Generation and Editing. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH 2024. 43(4). Article No. 44. July-August 2024. |
|
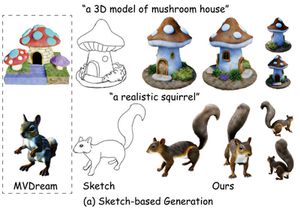 |
Abstract: Existing text-based 3D generation methods generate attractive results but lack detailed geometry control. Sketches, known for their conciseness and expressiveness, have contributed to intuitive 3D modeling but are confined to producing texture-less mesh models within predefined categories. Integrating sketch and text simultaneously for 3D generation promises enhanced control over geometry and appearance but faces challenges from 2D-to-3D translation ambiguity and multi-modal condition integration. Moreover, further editing of 3D models in arbitrary views will give users more freedom to customize their models. However, it is difficult to achieve high generation quality, preserve unedited regions, and manage proper interactions between shape components. To solve the above issues, we propose a text-driven 3D content generation and editing method, SketchDream, which supports NeRF generation from given hand-drawn sketches and achieves free-view sketch-based local editing. To tackle the 2D-to-3D ambiguity challenge, we introduce a sketch-based multi-view image generation diffusion model, which leverages depth guidance to establish spatial correspondence. A 3D ControlNet with a 3D attention module is utilized to control multi-view images and ensure their 3D consistency. To support local editing, we further propose a coarse-to-fine editing approach: the coarse phase analyzes component interactions and provides 3D masks to label edited regions, while the fine stage generates realistic results with refined details by local enhancement. Extensive experiments validate that our method generates higher-quality results compared with a combination of 2D ControlNet and image-to-3D generation techniques and achieves detailed control compared with existing diffusion-based 3D editing approaches. |
Keyu Wu, Lingchen Yang, Zhiyi Kuang, Yao Feng, Xutao Han, Yuefan Shen, Hongbo Fu, Kun Zhou, and Youyi Zheng. MonoHair: High-Fidelity Hair Modeling from a Monocular Video. CVPR 2024. June 2024. Oral Presentation |
|
 |
Abstract: Undoubtedly, high-fidelity 3D hair is crucial for achieving realism, artistic expression, and immersion in computer graphics. While existing 3D hair modeling methods have achieved impressive performance, the challenge of achieving high-quality hair reconstruction persists: they either require strict capture conditions, making practical applications difficult, or heavily rely on learned prior data, obscuring fine-grained details in images. To address these challenges, we propose a generic framework to achieve high-fidelity hair reconstruction from a monocular video, without specific requirements for environments. Our approach bifurcates the hair modeling process into two main stages: precise exterior reconstruction and interior structure inference. The exterior is meticulously crafted using our Patch-based Multi-View Optimization (PMVO). This method strategically collects and integrates hair information from multiple views, independent of prior data, to produce a high-fidelity exterior 3D line map. This map not only captures intricate details but also facilitates the inference of the hair’s inner structure. For the interior, we employ a data-driven, multi-view 3D hair reconstruction method. This method utilizes 2D structural renderings derived from the reconstructed exterior, mirroring the synthetic 2D inputs used during training. This alignment effectively bridges the domain gap between our training data and real-world data, thereby enhancing the accuracy and reliability of our interior structure inference. Lastly, we generate a strand model and resolve the directional ambiguity by our hair growth algorithm. Our experiments demonstrate that our method exhibits robustness across diverse hairstyles and achieves state-of-the-art performance. |
Ziqi Cai, Kaiwen Jiang, Shu-Yu Chen, Yu-Kun Lai, Hongbo Fu, and Lin Gao. Real-time 3D-aware Portrait Video Relighting. CVPR 2024. June 2024. Poster Highlight |
|
 |
Abstract: Synthesizing realistic videos of talking faces under custom lighting conditions and viewing angles benefits various downstream applications like video conferencing. However, most existing relighting methods are either time-consuming or unable to adjust the viewpoints. In this paper, we present the first real-time 3D-aware method for relighting in-the-wild videos of talking faces based on Neural Radiance Fields (NeRF). Given an input portrait video, our method can synthesize talking faces under both novel views and novel lighting conditions with a photo-realistic and disentangled 3D representation. Specifically, we infer an albedo tri-plane, as well as a shading tri-plane based on a desired lighting condition for each video frame with fast dual-encoders. We also leverage a temporal consistency network to ensure smooth transitions and reduce flickering artifacts. Our method runs at 32.98 fps on consumer-level hardware and achieves state-of-the-art results in terms of reconstruction quality, lighting error, lighting instability, temporal consistency and inference speed. We demonstrate the effectiveness and interactivity of our method on various portrait videos with diverse lighting and viewing conditions. |
Hui Ye*, Jia Ye Leng*, Pengfei Xu, Karan Singh, and Hongbo Fu. ProInterAR: A Visual Programming Platform for Creating Immersive AR Interactions. CHI 2024. Article No. 610. May 2024. |
|
 |
Abstract: AR applications commonly contain diverse interactions among different AR contents. Creating such applications requires creators to have advanced programming skills for scripting interactive behaviors of AR contents, repeated transferring and adjustment of virtual contents from virtual to physical scenes, testing by traversing between desktop interfaces and target AR scenes, and digitalizing AR contents. Existing immersive tools for prototyping/authoring such interactions are tailored for domain-specific applications. To support programming general interactive behaviors of real object(s)/environment(s) and virtual object(s)/environment(s) for novice AR creators, we propose ProInterAR, an integrated visual programming platform to create immersive AR applications with a tablet and an AR-HMD. Users can construct interaction scenes by creating virtual contents and augmenting real contents from the view of an AR-HMD, script interactive behaviors by stacking blocks from a tablet UI, and then execute and control the interactions in the AR scene. We showcase a wide range of AR application scenarios enabled by ProInterAR, including AR game, AR teaching, sequential animation, AR information visualization, etc. Two usability studies validate that novice AR creators can easily program various desired AR applications using ProInterAR. |
Shao-Kui Zhang, Jia-Hong Liu, Yike Li, Tianyi Xiong, Ke-Xin Ren, Hongbo Fu, and Song-Hai Zhang. Automatic Generation of Commercial Scenes. MM 2023. 1137-1147. Oct. 2023. |
|
 |
Abstract: Commercial scenes such as markets and shops are everyday scenes for both virtual scenes and real-world interior designs. However, existing literature on interior scene synthesis mainly focuses on formulating and optimizing residential scenes such as bedrooms, living rooms, etc. Existing literature typically presents a set of relations among objects. It recognizes each furniture object as the smallest unit while optimizing a residential room. However, object relations become less critical in commercial scenes since shelves are often placed next to each other so pre-calculated relations of objects are less needed. Instead, interior designers resort to evaluating how groups of objects perform in commercial scenes, i.e., the smallest unit to be evaluated is a group of objects. This paper presents a system automatically synthesizes market-like commercial scenes in virtual environments. Following the rules of commercial layout design, we parameterize groups of objects as "patterns" contributing to a scene. Each pattern directly yields a human-centric routine locally, provides potential connectivity with other routines, and derives the arrangements of objects concerning itself according to the assigned parameters. In order to optimize a scene, the patterns are iteratively multiplexed to insert new routines or modify existing ones under a set of constraints derived from commercial layout designs. Through extensive experiments, we demonstrate the ability of our framework to generate plausible and practical commercial scenes. |
Yiqian Wu, Jing Zhang, Hongbo Fu, and Xiaogang Jin. LPFF: A Portrait Dataset for Face Generators Across Large Poses. ICCV 2023. 20327-20337. Oct. 2023. |
|
 |
Abstract: The creation of 2D realistic facial images and 3D face shapes using generative networks has been a hot topic in recent years. Existing face generators exhibit exceptional performance on faces in small to medium poses (with respect to frontal faces) but struggle to produce realistic results for large poses. The distorted rendering results on large poses in 3D-aware generators further show that the generated 3D face shapes are far from the distribution of 3D faces in reality. We find that the above issues are caused by the training dataset's pose imbalance. In this paper, we present LPFF, a large-pose Flickr face dataset comprised of 19,590 high-quality real large-pose portrait images. We utilize our dataset to train a 2D face generator that can process large-pose face images, as well as a 3D-aware generator that can generate realistic human face geometry. To better validate our pose-conditional 3D-aware generators, we develop a new FID measure to evaluate the 3D-level performance. Through this novel FID measure and other experiments, we show that LPFF can help 2D face generators extend their latent space and better manipulate the large-pose data, and help 3D-aware face generators achieve better view consistency and more realistic 3D reconstruction results. |
Kaiwen Jiang, Shu-Yu Chen, Hongbo Fu, and Lin Gao. NeRFFaceLighting: Implicit and Disentangled Face Lighting Representation Leveraging Generative Prior in Neural Radiance Fields. ACM Transactions on Graphics. 42(3). Article No. 35. June 2023. |
|
 |
Abstract: 3D-aware portrait lighting control is an emerging and promising domain, thanks to the recent advance of generative adversarial networks and neural radiance fields. Existing solutions typically try to decouple the lighting from the geometry and appearance for disentangled control with an explicit lighting representation (e.g., Lambertian or Phong). However, they either are limited to a constrained lighting condition (e.g., directional light) or demand a tricky-to-fetch dataset as supervision for the intrinsic compositions (e.g., the albedo). We propose NeRFFaceLighting to explore an implicit representation for portrait lighting based on the pretrained tri-plane representation to address the above limitations. We approach this disentangled lighting-control problem by distilling the shading from the original fused representation of both appearance and lighting (i.e., one tri-plane) to their disentangled representations (i.e., two tri-planes) with the conditional discriminator to supervise the lighting effects. We further carefully design the regularization to reduce the ambiguity of such decomposition and enhance the ability of generalization to unseen lighting conditions. Moreover, our method can be extended to enable 3D-aware real portrait relighting. Through extensive quantitative and qualitative evaluations, we demonstrate the superior 3D-aware lighting control ability of our model compared to alternative and existing solutions. |
Lin Gao, Feng-Lin Liu, Shu-Yu Chen, Kaiwen Jiang, Chun-Peng Li, Yu-Kun Lai, and Hongbo Fu. SketchFaceNeRF: Sketch-based Facial Generation and Editing in Neural Radiance Fields. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH 2023. 42(4). Article No. 159. July 2023. |
|
 |
Abstract: Realistic 3D facial generation based on Neural Radiance Fields (NeRFs) from 2D sketches benefits various applications. Despite the high realism of free-view rendering results of NeRFs, it is tedious and difficult for artists to achieve detailed 3D control and manipulation. Meanwhile, due to its conciseness and expressiveness, sketching has been widely used for 2D facial image generation and editing. Applying sketching to NeRFs is challenging due to the inherent uncertainty for 3D generation with 2D constraints, a significant gap in content richness when generating faces from sparse sketches, and potential inconsistencies for sequential multi-view editing given only 2D sketch inputs. To address these challenges, we present SketchFaceNeRF, a novel sketch-based 3D facial NeRF generation and editing method, to produce free-view photo-realistic images. To solve the challenge of sketch sparsity, we introduce a Sketch Tri-plane Prediction net to first inject the appearance into sketches, thus generating features given reference images to allow color and texture control. Such features are then lifted into compact 3D tri-planes to supplement the absent 3D information, which is important for improving robustness and faithfulness. However, during editing, consistency for unseen or unedited 3D regions is difficult to maintain due to limited spatial hints in sketches. We thus adopt a Mask Fusion module to transform free-view 2D masks (inferred from sketch editing operations) into the tri-plane space as 3D masks, which guide the fusion of the original and sketch-based generated faces to synthesize edited faces. We further design an optimization approach with a novel space loss to improve identity retention and editing faithfulness. Our pipeline enables users to flexibly manipulate faces from different viewpoints in 3D space, easily designing desirable facial models. Extensive experiments validate that our approach is superior to the state-of-the-art 2D sketch-based image generation and editing approaches in realism and faithfulness. |
Hui Ye*, Jiaye Leng*, Chufeng Xiao*, Lili Wang, and Hongbo Fu. ProObjAR: Prototyping Spatially-aware Interactions of Smart Objects with AR-HMD. CHI 2023. Article No. 457. April 23 - 28, 2023. |
|
 |
Abstract: The rapid advances in technologies have brought new interaction paradigms of smart objects (e.g., digital devices) beyond digital device screens. By utilizing spatial properties, configurations, and movements of smart objects, designing spatial interaction, which is one of the emerging interaction paradigms, efficiently promotes engagement with digital content and physical facility. However, as an important phase of design, prototyping such interactions still remains challenging, since there is no ad-hoc approach for this emerging paradigm. Designers usually rely on methods that require fixed hardware setup and advanced coding skills to script and validate early-stage concepts. These requirements restrict the design process to a limited group of users in indoor scenes. To facilitate the prototyping to general usages, we aim to figure out the design difficulties and underlying needs of current design processes for spatially-aware object interactions by empirical studies. Besides, we explore the design space of the spatial interaction for smart objects and discuss the design space in an input-output spatial interaction model. Based on these findings, we present ProObjAR, an all-in-one novel prototyping system with an Augmented Reality Head Mounted Display (AR-HMD). Our system allows designers to easily obtain the spatial data of smart objects being prototyped, specify spatially-aware interactive behaviors from an input-output event triggering workflow, and test the prototyping results in situ. From the user study, we find that ProObjAR simplifies the design procedure and increases design efficiency to a large extent and thus advancing the development of spatially-aware applications in smart ecosystems. |
Xiaowei Chen, Xiao Jiang, Jiawei Fang, Shihui Guo, Juncong Lin, Minghong Liao, Guoliang Luo, and Hongbo Fu. DisPad: Flexible On-Body Displacement of Fabric Sensors for Robust Joint-Motion Tracking. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT). 7(1). Article No. 5. March 2023. |
|
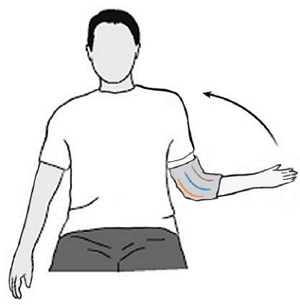 |
Abstract: The last few decades have witnessed an emerging trend of wearable soft sensors; however, there are important signal-processing challenges for soft sensors that still limit their practical deployment. They are error-prone when displaced, resulting in significant deviations from their ideal sensor output. In this work, we propose a novel prototype that integrates an elbow pad with a sparse network of soft sensors. Our prototype is fully bio-compatible, stretchable, and wearable. We develop a learning-based method to predict the elbow orientation angle and achieve an average tracking error of 9.82 degrees for single-user multi-motion experiments. With transfer learning, our method achieves the average tracking errors of 10.98 degrees and 11.81 degrees across different motion types and users, respectively. Our core contributions lie in a solution that realizes robust and stable human joint motion tracking across different device displacements. |
Fengyi Fang, Hongwei Zhang, Lishuang Zhan, Shihui Guo, Minying Zhang, Juncong Lin, Yipeng Qin, and Hongbo Fu. Handwriting Velcro: Endowing AR Glasses with Personalized and Posture-adaptive Text Input Using Flexible Touch Sensor. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT). 6(4). Article No. 163. December 2022. |
|
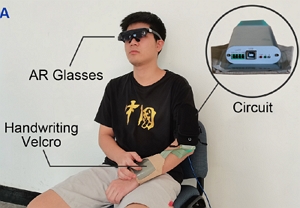 |
Abstract: The diverse demands required by different input scenarios can hardly be met by the small number of fixed input postures offered by existing solutions. In this paper, we present Handwriting Velcro, a novel text input solution for AR glasses based on flexible touch sensors. The distinct advantage of our system is that it can easily stick to different body parts, thus endowing AR glasses with posture-adaptive handwriting input. We explored the design space of on-body device positions and identified the best interaction positions for various user postures. To flatten users’ learning curves, we adapt our device to the established writing habits of different users by training a 36-character (i.e., A-Z, 0-9) recognition neural network in a human-in-the-loop manner. Such a personalization attempt ultimately achieves a low error rate of 0.005 on average for users with different writing styles. Subjective feedback shows that our solution has a good performance in system practicability and social acceptance. Empirically, we conducted a heuristic study to explore and identify the best interaction Position-Posture Correlation. Experimental results show that our Handwriting Velcro excels similar work [6] and commercial product in both practicality (12.3 WPM) and user-friendliness in different contexts. [Paper] |
Chufeng Xiao*, Wanchao Su* (joint first author), Jing Liao, Zhouhui Lian, Yi-Zhe Song, and Hongbo Fu. DifferSketching: How Differently Do People Sketch 3D Objects?. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH Asia 2022. 41(6). Article No. 264. December 2022. |
|
 |
Abstract: Multiple sketch datasets have been proposed to understand how people draw 3D objects. However, such datasets are often of small scale and cover a small set of objects or categories. In addition, these datasets contain freehand sketches mostly from expert users, making it difficult to compare the drawings by expert and novice users, while such comparisons are critical in informing more effective sketch-based interfaces for either user groups. These observations motivate us to analyze how differently people with and without adequate drawing skills sketch 3D objects. We invited 70 novice users and 38 expert users to sketch 136 3D objects, which were presented as 362 images rendered from multiple views. This leads to a new dataset of 3,620 freehand multi-view sketches, which are registered with their corresponding 3D objects under certain views. Our dataset is an order of magnitude larger than the existing datasets. We analyze the collected data at three levels, i.e., sketch-level, stroke-level, and pixel-level, under both spatial and temporal characteristics, and within and across groups of creators. We found that the drawings by professionals and novices show significant differences at stroke-level, both intrinsically and extrinsically. We demonstrate the usefulness of our dataset in two applications: (i) freehand-style sketch synthesis, and (ii) posing it as a potential benchmark for sketch-based 3D reconstruction. |
Pengfei Xu, Yifan Li, Zhijin Yang, Weiran Shi, Hongbo Fu, and Hui Huang. Hierarchical Layout Blending with Recursive Optimal Correspondence. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH Asia 2022. 41(6). Article No. 249. December 2022. |
|
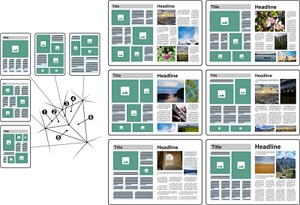 |
Abstract: We present a novel method for blending hierarchical layouts with semantic labels. The core of our method is a hierarchical structure correspondence algorithm, which recursively finds optimal substructure correspondences, achieving a globally optimal correspondence between a pair of hierarchical layouts. This correspondence is consistent with the structures of both layouts, allowing us to define the union of the layouts’ structures. The resulting compound structure helps extract intermediate layout structures, from which blended layouts can be generated via an optimization approach. The correspondence also defines a similarity measure between layouts in a hierarchically structured view. Our method provides a new way for novel layout creation. The introduced structural similarity measure regularizes the layouts in a hyperspace. We demonstrate two applications in this paper, i.e., exploratory design of novel layouts and sketch-based layout retrieval, and test them on a magazine layout dataset. The effectiveness and feasibility of these two applications are confirmed by the user feedback and the extensive results. |
Kaiwen Jiang, Shu-Yu Chen, Feng-Lin Liu, Hongbo Fu, and Lin Gao. NeRFFaceEditing: Disentangled Face Editing in Neural Radiance Fields. ACM SIGGRAPH Asia 2022 Conference Papers. Article No. 31. December 2022. Extended version in IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI). 47(4): 2533 - 2544. April 2025. |
|
 |
Abstract: Recent methods for synthesizing 3D-aware face images have achieved rapid development thanks to neural radiance fields, allowing for high quality and fast inference speed. However, existing solutions for editing facial geometry and appearance independently usually require retraining and are not optimized for the recent work of generation, thus tending to lag behind the generation process. To address these issues, we introduce NeRFFaceEditing, which enables editing and decoupling geometry and appearance in the pretrained tri-plane-based neural radiance field while retaining its high quality and fast inference speed. Our key idea for disentanglement is to use the statistics of the tri-plane to represent the high-level appearance of its corresponding facial volume. Moreover, we leverage a generated 3D-continuous semantic mask as an intermediary for geometry editing. We devise a geometry decoder (whose output is unchanged when the appearance changes) and an appearance decoder. The geometry decoder aligns the original facial volume with the semantic mask volume. We also enhance the disentanglement by explicitly regularizing rendered images with the same appearance but different geometry to be similar in terms of color distribution for each facial component separately. Our method allows users to edit via semantic masks with decoupled control of geometry and appearance. Both qualitative and quantitative evaluations show the superior geometry and appearance control abilities of our method compared to existing and alternative solutions. |
Zhiyi Kuang, Yiyang Chen, Hongbo Fu, Kun Zhou, and Youyi Zheng. DeepMVSHair: Deep Hair Modeling from Sparse Views. ACM SIGGRAPH Asia 2022 Conference Papers. Article No. 10. December 2022. |
|
 |
Abstract: We present DeepMVSHair, the first deep learning-based method for multi-view hair strand reconstruction. The key component of our pipeline is HairMVSNet, a differentiable neural architecture which represents a spatial hair structure as a continuous 3D hair growing direction field implicitly. Specifically, given a 3D query point, we decide its occupancy value and direction from observed 2D structure features. With the query point’s pixel-aligned features from each input view, we utilize a view-aware transformer encoder to aggregate anisotropic structure features to an integrated representation, which is decoded to yield 3D occupancy and direction at the query point. HairMVSNet effectively gathers multi-view hair structure features and preserves high-frequency details based on this implicit representation. Guided by HairMVSNet, our hair-growing algorithm produces results faithful to input multi-view images. We propose a novel image-guided multi-view strand deformation algorithm to enrich modeling details further. Extensive experiments show that the results by our sparse-view method are comparable to those by state-of-the-art dense multi-view methods and significantly better than those by single-view and sparse-view methods. In addition, our method is an order of magnitude faster than previous multi-view hair modeling methods. |
Feng-Lin Liu, Shu-Yu Chen, Yu-Kun Lai, Chunpeng Li, Yue-Ren Jiang, Hongbo Fu, and Lin Gao. DeepFaceVideoEditing: Sketch-based Deep Editing of Face Videos. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH 2022. 41(4). Article No. 167. August 2022. |
|
 |
Abstract: Sketches, which are simple and concise, have been used in recent deep image synthesis methods to allow intuitive generation and editing of facial images. However, it is nontrivial to extend such methods to video editing due to various challenges, ranging from appropriate manipulation propagation and fusion of multiple editing operations to ensure temporal coherence and visual quality. To address these issues, we propose a novel sketch-based facial video editing framework, in which we represent editing manipulations in latent space and propose specific propagation and fusion modules to generate high-quality video editing results based on StyleGAN3. Specifically, we first design an optimization approach to represent sketch editing manipulations by editing vectors, which are propagated to the whole video sequence using a proper strategy to cope with different editing needs. Specifically, input editing operations are classified into two categories: temporally consistent editing and temporally variant editing. The former (e.g., change of face shape) is applied to the whole video sequence directly, while the latter (e.g., change of facial expression or dynamics) is propagated with the guidance of expression or only affects adjacent frames in a given time window. Since users often perform different editing operations in multiple frames, we further present a region-aware fusion approach to fuse diverse editing effects. Our method supports video editing on facial structure and expression movement by sketch, which cannot be achieved by previous works. Both qualitative and quantitative evaluations show the superior editing ability of our system to existing and alternative solutions. |
Zeyu Hu*, Xuyang Bai*, Runze Zhang, Xin Wang, Guangyuan Sun, Hongbo Fu, and Chiew-Lan Tai. LiDAL: Inter-frame Uncertainty Based Active Learning for 3D LiDAR Semantic Segmentation. ECCV 2022. October 2022. (Acceptance rate: 28%) |
|
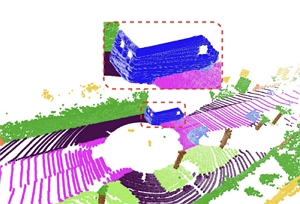 |
Abstract: We propose LiDAL, a novel active learning method for 3D LiDAR semantic segmentation by exploiting inter-frame uncertainty among LiDAR frames. Our core idea is that a well-trained model should generate robust results irrespective of viewpoints for scene scanning and thus the inconsistencies in model predictions across frames provide a very reliable measure of uncertainty for active sample selection. To implement this uncertainty measure, we introduce new inter-frame divergence and entropy formulations, which serve as the metrics for active selection. Moreover, we demonstrate additional performance gains by predicting and incorporating pseudo-labels, which are also selected using the proposed inter-frame uncertainty measure. Experimental results validate the effectiveness of LiDAL: we achieve 95% of the performance of fully supervised learning with less than 5% of annotations on the SemanticKITTI and nuScenes datasets, outperforming state-of-the-art active learning methods. |
Xuyang Bai*, Zeyu Hu*, Xinge Zhu, Qingqiu Huang, Yilun Chen, Hongbo Fu, and Chiew-Lan Tai. TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers. CVPR 2022. June 2022. (Acceptance rate: 25.3%) |
|
Abstract: LiDAR and camera are two important sensors for 3D object detection in autonomous driving. Despite the increasing popularity of sensor fusion in this field, the robustness against inferior image conditions, e.g., bad illumination and sensor misalignment, is under-explored. Existing fusion methods are easily affected by such conditions, mainly due to a hard association of LiDAR points and image pixels, established by calibration matrices. We propose TransFusion, a robust solution to LiDAR-camera fusion with a soft-association mechanism to handle inferior image conditions. Specifically, our TransFusion consists of convolutional backbones and a detection head based on a transformer decoder. The first layer of the decoder predicts initial bounding boxes from a LiDAR point cloud using a sparse set of object queries, and its second decoder layer adaptively fuses the object queries with useful image features, leveraging both spatial and contextual relationships. The attention mechanism of the transformer enables our model to adaptively determine where and what information should be taken from the image, leading to a robust and effective fusion strategy. We additionally design an image-guided query initialization strategy to deal with objects that are difficult to detect in point clouds. TransFusion achieves state-of-the-art performance on large-scale datasets. We provide extensive experiments to demonstrate its robustness against degenerated image quality and calibration errors. We also extend the proposed method to the 3D tracking task and achieve the 1st place in the leaderboard of nuScenes tracking, showing its effectiveness and generalization capability. |
|
Keyu Wu, Yifan Ye, Lingchen Yang, Hongbo Fu, Kun Zhou, and Youyi Zheng. NeuralHDHair: Automatic High-fidelity Hair Modeling from a Single Image Using Implicit Neural Representations. CVPR 2022. June 2022. (Acceptance rate: 25.3%) |
|
 |
Abstract: Undoubtedly, high-fidelity 3D hair plays an indispensable role in digital humans. However, existing monocular hair modeling methods are either tricky to deploy in digital systems (e.g., due to their dependence on complex user interactions or large databases) or can produce only a coarse geometry. In this paper, we introduce NeuralHDHair, a flexible, fully automatic system for modeling high-fidelity hair from a single image. The key enablers of our system are two carefully designed neural networks: an IRHairNet (Implicit representation for hair using neural network) for inferring high-fidelity 3D hair geometric features (3D orientation field and 3D occupancy field) hierarchically and a GrowingNet(Growing hair strands using neural network) to efficiently generate 3D hair strands in parallel. Specifically, we perform a coarse-to-fine manner and propose a novel voxel-aligned implicit function (VIFu) to represent the global hair feature, which is further enhanced by the local details extracted from a hair luminance map. To improve the efficiency of a traditional hair growth algorithm, we adopt a local neural implicit function to grow strands based on the estimated 3D hair geometric features. Extensive experiments show that our method is capable of constructing a high-fidelity 3D hair model from a single image, both efficiently and effectively, and achieves the-state-of-the-art performance. [Paper] |
Hui Ye* and Hongbo Fu. ProGesAR: Mobile AR Prototyping for Proxemic and Gestural Interactions with Real-world IoT Enhanced Spaces. CHI 2022. Article No. 130. April 30 - May 5 2022. |
|
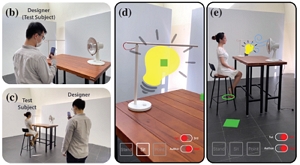 |
Abstract:Real-world IoT enhanced spaces involve diverse proximity- and gesture-based interactions between users and IoT devices/objects. Prototyping such interactions benefits various applications like the conceptual design of ubicomp space. AR (Augmented Reality) prototyping provides a flexible way to achieve early-stage designs by overlaying digital contents on real objects or environments. However, existing AR prototyping approaches have focused on prototyping AR experiences or context-aware interactions from the first-person view instead of full-body proxemic and gestural (proges for short) interactions of real users in the real world. In this work, we conducted interviews to figure out the challenges of prototyping pro-ges interactions in real-world IoT enhanced spaces. Based on the findings, we present ProGesAR, a mobile AR tool for prototyping pro-ges interactions of a subject in a real environment from a third-person view, and examining the prototyped interactions from both the first- and third- person views. Our interface supports the effects of virtual assets dynamically triggered by a single subject, with the triggering events based on four features: location, orientation, gesture, and distance. We conduct a preliminary study by inviting participants to prototype in a freeform manner using ProGesAR. The early-stage findings show that with ProGesAR, users can easily and quickly prototype their design ideas about pro-ges interactions. |
Yuefan Shen, Hongbo Fu, Zhongshuo Du, Xiang Chen, Evgeny Burnaev, Denis Zorin, Kun Zhou, and Youyi Zheng. GCN-Denoiser: Mesh Denoising with Graph Convolutional Networks. ACM Transactions on Graphics (TOG). 41(1): Article No. 8. February 2022. |
|
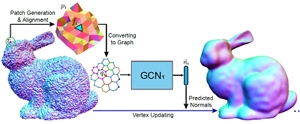 |
Abstract: In this paper, we present GCN-Denoiser, a novel feature-preserving mesh denoising method based on graph convolutional networks (GCNs). Unlike previous learning-based mesh denoising methods that exploit hand-crafted or voxel-based representations for feature learning, our method explores the structure of a triangular mesh itself and introduces a graph representation followed by graph convolution operations in the dual space of triangles. We show such a graph representation naturally captures the geometry features while being lightweight for both training and inference. To facilitate effective feature learning, our network exploits both static and dynamic edge convolutions, which allow us to learn information from both the explicit mesh structure and potential implicit relations among unconnected neighbors. To better approximate an unknown noise function, we introduce a cascaded optimization paradigm to progressively regress the noise-free facet normals with multiple GCNs. GCN-Denoiser achieves the new state-of-the-art results in multiple noise datasets, including CAD models often containing sharp features and raw scan models with real noise captured from different devices. |
Chufeng Xiao*, Deng Yu*, Xiaoguang Han, Youyi Zheng, and Hongbo Fu. SketchHairSalon: Deep Sketch-based Hair Image Synthesis. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH Asia 2021. 40(6): Article No. 216. December 2021. |
|
 |
Abstract: Recent deep generative models allow real-time generation of hair images from sketch inputs. Existing solutions often require a user-provided binary mask to specify a target hair shape. This not only costs users extra labor but also fails to capture complicated hair boundaries. Those solutions usually encode hair structures via orientation maps, which, however, are not very effective to encode complex structures.We observe that colored hair sketches already implicitly define target hair shapes as well as hair appearance and are more flexible to depict hair structures than orientation maps. Based on these observations, we present SketchHairSalon, a two-stage framework for generating realistic hair images directly from freehand sketches depicting desired hair structure and appearance. At the first stage, we train a network to predict a hair matte from an input hair sketch, with an optional set of nonhair strokes. At the second stage, another network is trained to synthesize the structure and appearance of hair images from the input sketch and the generated matte. To make the networks in the two stages aware of longterm dependency of strokes, we apply self-attention modules to them. To train these networks, we present a new moderately large dataset, containing diverse hairstyles with annotated hair sketch-image pairs and corresponding hair mattes. Two efficient methods for sketch completion are proposed to automatically complete repetitive braided parts and hair strokes, respectively, thus reducing the workload of users. Based on the trained networks and the two sketch completion strategies, we build an intuitive interface to allow even novice users to design visually pleasing hair images exhibiting various hair structures and appearance via freehand sketches. The qualitative and quantitative evaluations show the advantages of the proposed system over the existing or alternative solutions. [Paper, Video (@Vimeo), Video (@Youtube), Video (by "Two Minute Papers"), Code, Project] |
Zeyu Hu*, Xuyang Bai*, Jiaxiang Shang, Runze Zhang, Jiayu Dong, Xin Wang, Guangyuan Sun, Hongbo Fu, and Chiew-Lan Tai. VMNet: Voxel-Mesh Network for Geodesic-Aware 3D Semantic Segmentation. ICCV 2021. Octoboer 2021. (Acceptance rate: 25.9%) Oral Presentation |
|
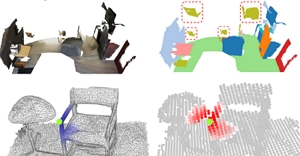 |
Abstract: In recent years, sparse voxel-based methods have become the state-of-the-arts for 3D semantic segmentation of indoor scenes, thanks to the powerful 3D CNNs. Nevertheless, being oblivious to the underlying geometry, voxel-based methods suffer from ambiguous features on spatially close objects and struggle with handling complex and irregular geometries due to the lack of geodesic information. In view of this, we present Voxel-Mesh Network (VMNet), a novel 3D deep architecture that operates on the voxel and mesh representations leveraging both the Euclidean and geodesic information. Intuitively, the Euclidean information extracted from voxels can offer contextual cues representing interactions between nearby objects, while the geodesic information extracted from meshes can help separate objects that are spatially close but have disconnected surfaces. To incorporate such information from the two domains, we design an intra-domain attentive module for effective feature aggregation and an inter-domain attentive module for adaptive feature fusion. Experimental results validate the effectiveness of VMNet: specifically, on the challenging ScanNet dataset for large-scale segmentation of indoor scenes, it outperforms the state-of-the-art SparseConvNet and MinkowskiNet (74.6% vs 72.5% and 73.6% in mIoU) with a simpler network structure (17M vs 30M and 38M parameters). |
Jingyuan Liu*, Mingyi Shi, Qifeng Chen, Hongbo Fu, and Chiew-Lan Tai. Normalized Human Pose Features for Human Action Video Alignment. ICCV 2021. Octoboer 2021. (Acceptance rate: 25.9%) Oral Presentation
|
|
 |
Abstract: We present a novel approach for extracting human pose features from human action videos. The goal is to let the pose features capture only the poses of the action while being invariant to other factors, including video backgrounds, the video subject's anthropometric characteristics and viewpoints. Such human pose features facilitate the comparison of pose similarity and can be used for down-stream tasks, such as human action video alignment and pose retrieval. The key to our approach is to first normalize the poses in the video frames by retargeting the poses onto a pre-defined 3D skeleton to not only disentangle subject physical features, such as bone lengths and ratios, but also to unify global orientations of the poses. Then the normalized poses are mapped to a pose embedding space of high-level features, learned via unsupervised metric learning. We evaluate the effectiveness of our normalized features both qualitatively by visualizations, and quantitatively by a video alignment task on the Human3.6M dataset and an action recognition task on the Penn Action dataset. . |
Zhijin Yang, Pengfei Xu, Hongbo Fu, and Hui Huang. WireRoom: Model-guided Explorative Design of Abstract Wire Art. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH 2021. 40(4). Article No. 128. August 2021. (Acceptance rate: 35.0%) |
|
 |
Abstract: We present WireRoom, a computational framework for the intelligent design of abstract 3D wire art to depict a given 3D model. Our algorithm generates a set of 3D wire shapes from the 3D model with informative, visually pleasing, and concise structures. It is achieved by solving a dynamic travelling salesman problem on the surface of the 3D model with a multi-path expansion approach. We introduce a novel explorative computational design procedure by taking the generated wire shapes as candidates, avoiding manual design of the wire shape structure. We compare our algorithm with a baseline method and conduct a user study to investigate the usability of the framework and the quality of the produced wire shapes. The results of the comparison and user study confirm that our framework is effective for producing informative, visually pleasing, and concise wire shapes. |
Shu-Yu Chen, Feng-Lin Liu, Yu-Kun Lai, Paul Rosin, Chun-Peng Li, Hongbo Fu, and Lin Gao. DeepFaceEditing: Deep Face Generation and Editing with Disentangled Geometry and Appearance Control. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH 2021. 40(4). Article No. 90. August 2021. (Acceptance rate: 35.0%) |
|
 |
Abstract: Recent facial image synthesis methods have been mainly based on conditional generative models. Sketch-based conditions can effectively describe the geometry of faces, including the contours of facial components, hair structures, as well as salient edges (e.g., wrinkles) on face surfaces but lack effective control of appearance, which is influenced by color, material, lighting condition, etc. To have more control of generated results, one possible approach is to apply existing disentangling works to disentangle face images into geometry and appearance representations. However, existing disentangling methods are not optimized for human face editing, and cannot achieve fine control of facial details such as wrinkles. To address this issue, we propose DeepFaceEditing, a structured disentanglement framework specifically designed for face images to support face generation and editing with disentangled control of geometry and appearance. We adopt a local-to-global approach to incorporate the face domain knowledge: local component images are decomposed into geometry and appearance representations, which are fused consistently using a global fusion module to improve generation quality.We exploit sketches to assist in extracting a better geometry representation, which also supports intuitive geometry editing via sketching. The resulting method can either extracts the geometry and appearance representations from face images, or directly extracts the geometry representation from face sketches. Such representations allow users to easily edit and synthesize face images, with decoupled control of their geometry and appearance. Both qualitative and quantitative evaluations show the superior detail and appearance control abilities of our method compared to state-of-the-art methods. |
Shi-Sheng Huang, Ze-Yu Ma, Tai-Jiang Mu, Hongbo Fu, and Shi-Min Hu. Supervoxel Convolution for Online 3D Semantic Segmentation. ACM Transactions on Graphics (TOG). 43(3). Article No. 34. June 2021. |
|
 |
Abstract: Online 3D semantic segmentation, which aims to perform real-time 3D scene reconstruction along with semantic segmentation, is an important but challenging topic. A key challenge is to strike a balance between efficiency and segmentation accuracy. There are very few deep learning based solutions to this problem, since the commonly used deep representations based on volumetric-grids or points do not provide efficient 3D representation and organization structure for online segmentation. Observing that on-surface supervoxels, i.e., clusters of on-surface voxels, provide a compact representation of 3D surfaces and brings efficient connectivity structure via supervoxel clustering, we explore a supervoxel-based deep learning solution for this task. To this end, we contribute a novel convolution operation (SVConv) directly on supervoxels. SVConv can efficiently fuse the multi-view 2D features and 3D features projected on supervoxels during the online 3D reconstruction, and leads to an effective supervoxel-based convolutional neural network, termed as Supervoxel-CNN, enabling 2D-3D joint learning for 3D semantic prediction. With the Supervoxel-CNN, we propose a clustering-then-prediction online 3D semantic segmentation approach. The extensive evaluations on the public 3D indoor scene datasets show that our approach significantly outperforms the existing online semantic segmentation systems in terms of efficiency or accuracy. |
Lumin Yang, Jiajie Zhuang, Hongbo Fu, Xiangzhi Wei, Kun Zhou, and Youyi Zheng. SketchGNN: Semantic Sketch Segmentation with Graph Neural Networks. ACM Transactions on Graphics (TOG). 40(3). Article No. 28. Aug. 2021. |
|
 |
Abstract: We introduce SketchGNN, a convolutional graph neural network for semantic segmentation and labeling of freehand vector sketches. We treat an input stroke-based sketch as a graph, with nodes representing the sampled points along input strokes and edges encoding the stroke structure information. To predict the per-node labels, our SketchGNN uses graph convolution and a static-dynamic branching network architecture to extract the features at three levels, i.e., point-level, stroke-level, and sketch-level. SketchGNN significantly improves the accuracy of the state-of-the-art methods for semantic sketch segmentation (by 11.2% in the pixel-based metric and 18.2% in the component-based metric over a large-scale challenging SPG dataset) and has magnitudes fewer parameters than both image-based and sequence-based methods. |
Zhongjin Luo, Jie Zhou*, Heming Zhu, Dong Du, Xiaoguang Han, and Hongbo Fu. SimpModeling: Sketching Implicit Field to Guide Mesh Modeling for 3D Animalmorphic Head Design. UIST 2021. October 2021. (Acceptance rate: 25.9%). |
|
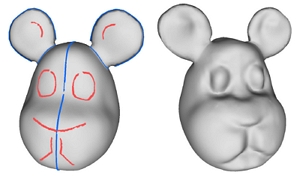 |
Abstract: Head shapes play an important role in designing 3D virtual characters.In this work, we propose a novel sketch-based interface for modeling animalmorphic heads - a very popular kind of heads in character design. Although sketching provides an easy way to depict desired shapes, it is challenging to infer dense geometric information from sparse line drawings. Recently, deepnet-based approaches have been taken to address this challenge and try to produce rich geometric details from very few strokes. However, which such methods reduce users' workload, they would cause less controllability of target shapes. This is mainly due to the uncertainty of neural prediction. Our system tackles this issue and provides more controllability from three aspects: 1) we separate coarse shape design and geometric detail specification into two stages and respectively provide different sketching ways; 2) in coarse model designing, sketches are used for both shape inference and geometric constraints to determine global geometry; 3) in both stages, we use the advanced implicit-based shape inference methods, which have better ability to handle the domain gap between freehand sketches and synthetic ones used for training. Experimental results confirm the effectiveness of our method and the usability of our interactive system. We also contribute a dataset of high-quality 3D animal heads, which are manually created by artists. [Paper, Video, Code, Presentation, Project] |
Xuyang Bai*, Zixin Luo, Lei Zhou, Hongkai Chen, Lei Li*, Zeyu Hu*, Hongbo Fu, and Chiew-Lan Tai. PointDSC: Robust Point Cloud Registration using Deep Spatial Consistency. CVPR 2021. June 2021. (Acceptance rate: 27.0%). |
|
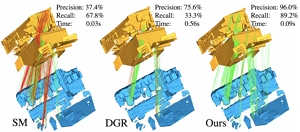 |
Abstract: Removing outlier correspondences is one of the critical steps for successful feature-based point cloud registration. Despite the increasing popularity of introducing deep learning techniques in this field, spatial consistency, which is essentially established by a Euclidean transformation between point clouds, has received almost no individual attention in existing learning frameworks. In this paper, we present PointDSC, a novel deep neural network that explicitly incorporates spatial consistency for pruning outlier correspondences. First, we propose a nonlocal feature aggregation module, weighted by both feature and spatial coherence, for feature embedding of the input correspondences. Second, we formulate a differentiable spectral matching module, supervised by pairwise spatial compatibility, to estimate the inlier confidence of each correspondence from the embedded features. With modest computation cost, our method outperforms the state-of-the-art handcrafted and learning-based outlier rejection approaches on several real-world datasets by a significant margin. We also show its wide applicability by combining PointDSC with different 3D local descriptors. |
Yu-Hui Wen, Zhipeng Yang (joint first author), Hongbo Fu, Lin Gao, Yannan Sun, and Yong-Jin Liu. Autoregressive Stylized Motion Synthesis with Generative Flow. CVPR 2021. June 2021. (Acceptance rate: 27.0%). |
|
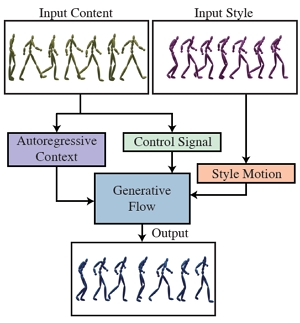 |
Abstract: Style-based motion synthesis is an important problem in many computer graphics and computer vision applications, including human animation, games, and robotics. Most existing deep learning methods for this problem are supervised and trained by registered motion pairs. In addition, these methods are often limited to yielding a deterministic output, given a pair of style and content motions. In this paper, we propose an unsupervised approach for motion style transfer by synthesizing stylized motions autoregressively using a generative flow modelM. Mis trained to maximize the exact likelihood of a collection of unlabeled motions, based on an autoregressive context of poses in previous frames and a control signal representing the movement of a root joint. Thanks to invertible flow transformations, latent codes that encode deep properties of motion styles are efficiently inferred byM. By combining the latent codes (from an input style motion S) with the autoregressive context and control signal (from an input content motion C),Moutputs a stylized motion which transfers style from S to C. Moreover, our model is probabilistic and is able to generate various plausible motions with a specific style. We evaluate the proposed model on motion capture datasets containing different human motion styles. Experiment results show that our model outperforms the state-of-the-art methods, despite not requiring manually labeled training data. |
Ying Jiang, Congyi Zhang, Hongbo Fu, Alberto Cannavo, Fabrizio Lamberti, Henry Lau, and Wenping Wang. HandPainter - 3D Sketching in VR with Hand-based Physical Proxy. CHI 2021. May 2021. (Acceptance rate: 26.3%). |
|
 |
Abstract: 3D sketching in virtual reality (VR) enables users to create 3D virtual objects intuitively and immersively. However, previous studies showed that mid-air drawing may lead to inaccurate sketches. To address this issue, we propose to use one hand as a canvas proxy and the index finger of the other hand as a 3D pen. To this end, we first performed a formative study to compare two-handed interaction with tablet-pen interaction for VR sketching. Based on the findings of this study, we designed HandPainter, a VR sketching system which focuses on the direct use of two hands for 3D sketching without requesting any tablet, pen, or VR controller. Our implementation is based on a pair of VR gloves, which provide hand tracking and gesture capture. We devised a set of intuitive gestures to control various functionalities required during 3D sketching, such as canvas panning and drawing positioning. We showed the effectiveness of HandPainter by presenting a number of sketching results and discussing the outcomes of a user study-based comparison with mid-air drawing and tablet-based sketching tools. |
Lingchen Yang, Zefeng Shi, Hongbo Fu, Yiqian Wu, Kun Zhou, and Youyi Zheng. iOrthoPredictor: Deep Prediction of Teeth Alignment in Single Images. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH Asia 2020. November/December 2020. (Acceptance rate: xx.x%) |
|
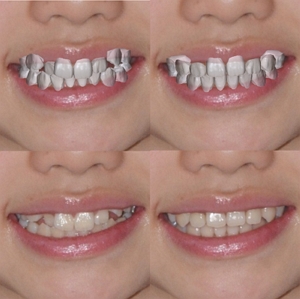 |
Abstract: In this paper, we present iOrthoPredictor, a novel system to visually predict the teeth alignment effect in a single photograph. Our system takes a frontal face image of a patient with visible malpositioned teeth along with the corresponding 3D teeth model as input, and generates a facial image with aligned teeth, mimicking the real orthodontic treatment effect. The key enabler of our method is an effective disentanglement of an explicit representation of the teeth geometry from the in-mouth appearance, where the accuracy of teeth geometry transformation is ensured by the 3D teeth model while the in-mouth appearance is modeled as a latent variable. The disentanglement enables us to achieve fine-scale geometry control over the alignment while retaining the original teeth attributes and lighting conditions. The whole pipeline consists of three deep neural networks: a UNet architecture to explicitly extract the 2D teeth silhouette maps representing the teeth geometry in the input photo, an encoder-decoder based generative model to synthesize the in-mouth appearance conditional on the teeth geometry, and a novel multilayer perceptron (MLP) based network to predict the aligned 3D teeth model. Extensive experimental results and a user study demonstrate that iOrthoPredictor is effective in generating high-quality visual prediction of teeth alignment effect, and readily applicable to industrial orthodontic treatments. |
Shu-Yu Chen, Wanchao Su* (joint first author), Lin Gao, Shihong Xia, and Hongbo Fu. DeepFaceDrawing: Deep Generation of Face Images from Sketches. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH 2020. 39(4). Article 72. July 2020. (Acceptance rate: xx.x%) |
|
 |
Abstract: Recent deep image-to-image translation techniques allow fast generation of face images from freehand sketches. However, existing solutions tend to overfit to sketches, thus requiring professional sketches or even edge maps as input. To address this issue, our key idea is to implicitly model the shape space of plausible face images and synthesize a face image in this space to approximate an input sketch. We take a local-to-global approach. We first learn feature embeddings of key face components, and push corresponding parts of input sketches towards underlying component manifolds defined by the feature vectors of face component samples. We also propose another deep neural network to learn the mapping from the embedded component features to realistic images with multi-channel feature maps as intermediate results to improve the information flow. Our method essentially uses input sketches as soft constraints and is thus able to produce high-quality face images even from rough and/or incomplete sketches. Our tool is easy to use even for non-artists, while still supporting fine-grained control of shape details. Both qualitative and quantitative evaluations show the superior generation ability of our system to existing and alternative solutions. The usability and expressiveness of our system are confirmed by a user study. |
Hui Ye*, Kin Chung Kwan* (joint first author), Wanchao Su*, and Hongbo Fu. ARAnimator: In-situ Character Animation in Mobile AR with User-defined Motion Gestures. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH 2020. 39(4). Article 83. July 2020. (Acceptance rate: xx.x%) |
|
 |
Abstract: Creating animated virtual AR characters closely interacting with real environments is interesting but difficult. Existing systems adopt video see-through approaches to indirectly control a virtual character in mobile AR, making close interaction with real environments not intuitive. In this work we use an AR-enabled mobile device to directly control the position and motion of a virtual character situated in a real environment. We conduct two guessability studies to elicit user-defined motions of a virtual character interacting with real environments, and a set of user-defined motion gestures describing specific character motions. We found that an SVM-based learning approach achieves reasonably high accuracy for gesture classification from the motion data of a mobile device. We present ARAnimator, which allows novice and casual animation users to directly represent a virtual character by an AR-enabled mobile phone and control its animation in AR scenes using motion gestures of the device, followed by animation preview and interactive editing through a video see-through interface. Our experimental results show that with ARAnimator, users are able to easily create in-situ character animations closely interacting with different real environments. |
Sheng Yang, Beichen Li, Yanpei Cao, Hongbo Fu, Yukun Lai, Leif Kobbelt, and Shi-Min Hu. Noise-Resilient Reconstruction of Panoramas and 3D Scenes using Robot-Mounted Unsynchronized Commodity RGB-D Cameras. ACM Transactions on Graphics (TOG) - presented at SIGGRAPH 2020. 39(5). Article No. 152. July 2020. |
|
 |
Abstract: We present a two-stage approach to first constructing 3D panoramas and then stitching them for noise-resilient reconstruction of large-scale indoor scenes. Our approach requires multiple unsynchronized RGB-D cameras, mounted on a robot platform which can perform in-place rotations at different locations in a scene. Such cameras rotate on a common (but unknown) axis, which provides a novel perspective for coping with unsynchronized cameras, without requiring sufficient overlap of their Field-of-View (FoV). Based on this key observation, we propose novel algorithms to track these cameras simultaneously. Furthermore, during the integration of raw frames onto an equirectangular panorama, we derive uncertainty estimates from multiple measurements assigned to the same pixels. This enables us to appropriately model the sensing noise and consider its influence, so as to achieve better noise resilience, and improve the geometric quality of each panorama and the accuracy of global inter-panorama registration. We evaluate and demonstrate the performance of our proposed method for enhancing the geometric quality of scene reconstruction from both real-world and synthetic scans. [Paper] |
Jingyuan Liu*, Hongbo Fu, and Chiew-Lan Tai. PoseTween: Pose-driven Tween Animation. UIST 2020. 971-804. (Acceptance rate: 21.6%). October 2020. |
|
 |
Abstract: Augmenting human action videos with visual effects often requires professional tools and skills. To make this more accessible by novice users, existing attempts have focused on automatically adding visual effects to faces and hands, or let virtual objects strictly track certain body parts, resulting in rigid-looking effects. We present PoseTween, an interactive system that allows novice users to easily add vivid virtual objects with their movement interacting with a moving subject in an input video. Our key idea is to leverage the motion of the subject to create pose-driven tween animations of virtual objects. With our tool, a user only needs to edit the properties of a virtual object with respect to the subject’s movement at keyframes, and the object is associated with certain body parts automatically. The properties of the object at intermediate frames are then determined by both the body movement and the interpolated object keyframe properties, producing natural object movements and interactions with the subject. We design a user interface to facilitate editing of keyframes and previewing animation results. Our user study shows that PoseTween significantly requires less editing time and fewer keyframes than using the traditional tween animation in making pose-driven tween animations for novice users. [Paper, Video, Presentation] |
Zeyu Hu*, Mingmin Zhen, Xuyang Bai*, Hongbo Fu, and Chiew-Lan Tai. JSENet: Joint Semantic Segmentation and Edge Detection Network for 3D Point Clouds. ECCV 2020. (Acceptance rate: 27.0%). August 2020. |
|
 |
Abstract: Semantic segmentation and semantic edge detection can be seen as two dual problems with close relationships in computer vision. Despite the fast evolution of learning-based 3D semantic segmentation methods, little attention has been drawn to the learning of 3D semantic edge detectors, even less to a joint learning method for the two tasks. In this paper, we tackle the 3D semantic edge detection task for the first time and present a new two-stream fully-convolutional network that jointly performs the two tasks. In particular, we design a joint refinement module that explicitly wires region information and edge information to improve the performances of both tasks. Further, we propose a novel loss function that encourages the network to produce semantic segmen- tation results with better boundaries. Extensive evaluations on S3DIS and ScanNet datasets show that our method achieves on par or better performance than the state-of-the-art methods for semantic segmenta- tion and outperforms the baseline methods for semantic edge detection. |
Lei Li*, Siyu Zhu, Hongbo Fu, Ping Tan, and Chiew-Lan Tai. End-to-End Learning Local Multi-view Descriptors for 3D Point Clouds. CVPR 2020. (Acceptance rate: 22.4%). June 2020. |
|
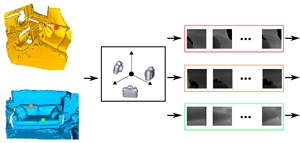 |
Abstract: In this work, we propose an end-to-end framework to learn local multi-view descriptors for 3D point clouds. Toadopt a similar multi-view representation, existing studies use hand-crafted viewpoints for rendering in a preprocessing stage, which is detached from the subsequent descriptor learning stage. In our framework, we integrate the multi-view rendering into neural networks by using a differentiable renderer, which allows the viewpoints to be optimizable parameters for capturing more informative local context of interest points. To obtain discriminative descriptors, we also design a soft-view pooling module to attentively fuse convolutional features across views. Extensive experiments on existing 3D registration benchmarks show that our method outperforms existing local descriptors both quantitatively and qualitatively. |
Xuyang Bai*, Zixin Luo, Lei Zhou, and Hongbo Fu, Long Quan, and Chiew-Lan Tai. D3Feat: Joint Learning of Dense Detection and Description of 3D Local Features. CVPR 2020. (Acceptance rate: 22.4%). June 2020. Oral Presentation |
|
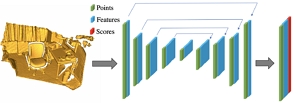 |
Abstract: A successful point cloud registration often lies on robust establishment of sparse matches through discriminative 3D local features. Despite the fast evolution of learning-based 3D feature descriptors, little attention has been drawn to the learning of 3D feature detectors, even less for a joint learning of the two tasks. In this paper, we leverage a 3D fully convolutional network for 3D point clouds, and propose a novel and practical learning mechanism that densely predicts both a detection score and a description feature for each 3D point. In particular, we propose a keypoint selection strategy that overcomes the inherent density variations of 3D point clouds, and further propose a self-supervised detector loss guided by the on-the-fly feature matching results during training. Finally, our method achieves state-of-the-art results in both indoor and outdoor scenarios, evaluated on 3DMatch and KITTI datasets, and shows its strong generalization ability on the ETH dataset. Towards practical use, we show that by adopting a reliable feature detector, sampling a smaller number of features is sufficient to achieve accurate and fast point cloud alignment. |
Pui Chung Wong*, Kening Zhu, Xing-Dong Yang, and Hongbo Fu. Exploring eyes-free bezel-initiated swipe on round
smartwatches. CHI 2020. (Acceptance rate: 24.31%). April 2020. |
|
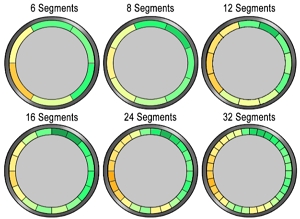 |
Abstract: Bezel-based gestures expand the interaction space of touch-screen devices (e.g., smartphones and smartwatches). Existing works have mainly focused on bezel-initiated swipe (BIS) on square screens. To investigate the usability of BIS onround smartwatches, we design six different circular bezellayouts, by dividing the bezel into 6, 8, 12, 16, 24, and 32 seg-ments. We evaluate the user performance of BIS on these sixlayouts in an eyes-free situation, since it can potentially bene-fit various usage scenarios, e.g., navigation with smartglasses.The results show that the performance of BIS is highly orien-tation dependent, and varies significantly among users Usingthe Support-Vector-Machine (SVM) model significantly in-creases the accuracy on 6-, 8-, 12-, and 16-segment layouts.We then compare the performance of personal and generalSVM models, and find that personal models significantly im-prove the accuracy for 8-, 12-, 16-, and 24-segment layouts.Lastly, we discuss the potential smartwatch applications en-abled by the BIS. |
Changqing Zou, Haoran Mo, Chengying Gao, Ruofei Du, and Hongbo Fu. Language-based Colorization of Scene Sketches. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH Asia 2019. 38(6). Article 233. November 2019. (Acceptance rate: 30.0%) |
|
 |
Abstract: Being natural to everyone, language-based inputs have demonstrated effective for various tasks such as object detection and image generation. This paper for the first time presents a language-based system for interactive colorization of scene sketches, based on their semantic comprehension. Compared with prior scribble-based interfaces, which require a minimum level of professional skills, our language-based interface is more natural for novice users. The proposed system is built upon deep neural networks trained on a large-scale repository of scene sketches and cartoon-style color images with text descriptions. Given a scene sketch, our system allows users, via language-based instructions, to interactively localize and colorize specific object instances to meet various colorization requirements in a progressive way. We demonstrate the effectiveness of our approach via comprehensive experimental results including alternative studies, comparison with the state-of-the-art, and generalization user studies. |
Lin Gao, Jie Yang, Tong Wu, Yu-Jie Yuan, Hongbo Fu, Yu-Kun Lai, and Hao Zhang. SDM-NET: Deep Generative Network for Structured Deformable Mesh. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH Asia 2019. 38(6). Article 243. November 2019. (Acceptance rate: 30.0%) |
|
 |
Abstract: We introduce SDM-NET, a deep generative neural network which produces structured deformable meshes. Specifically, the network is trained to generate a spatial arrangement of closed, deformable mesh parts, which respects the global part structure of a shape collection, e.g., chairs, airplanes, etc. Our key observation is that while the overall structure of a 3D shape can be complex, the shape can usually be decomposed into a set of parts, each homeomorphic to a box, and the finer-scale geometry of the part can be recovered by deforming the box. The architecture of SDM-NET is that of a two-level variational autoencoder (VAE). At the part level, a PartVAE learns a deformable model of part geometries. At the structural level, we train a Structured Parts VAE (SP-VAE), which jointly learns the part structure of a shape collection and the part geometries, ensuring a coherence between global shape structure and surface details. Through extensive experiments and comparisons with the state-of-the-art deep generative models of shapes, we demonstrate the superiority of SDM-NET in generating meshes with visual quality, flexible topology, and meaningful structures, which benefit shape interpolation and other subsequently modeling tasks. |
Zheer Xu, Pui Chung Wong*, Jun Gong, Te-Yen Wu, Aditya Shekhar Nittala, Xiaojun Bi, Jurgen Steimle, Hongbo Fu, Kening Zhu, and Xing-Dong Yang. TipText: Eyes Free Text Entry on a Fingertip Keyboard. UIST 2019. (Acceptance rate: 24.4%). October 2019. Best Paper Award |
|
 |
Abstract: In this paper, we propose and investigate a new text entry technique using micro thumb-tip gestures. Our technique features a miniature QWERTY keyboard residing invisibly on the first segment of the user’s index finger. Text entry can be carried out using the thumb-tip to tap the tip of the index finger. The keyboard layout was optimized for eyes-free input by utilizing a spatial model reflecting the users' natural spatial awareness of key locations on the index finger. We present our approach of designing and optimizing the keyboard layout through a series of user studies and computer simulated text entry tests over 1,146,484 possibilities in the design space. The outcome is a 2×3 grid with the letters highly confining to the alphabetic and spatial arrangement of QWERTY. Our user evaluation showed that participants achieved an average text entry speed of 11.9 WPM and were able to type as fast as 13.3 WPM towards the end of the experiment. |
Kin Chung Kwan*, and Hongbo Fu. Mobi3DSketch: 3D Sketching in Mobile AR. CHI 2019. (Acceptance rate: 23.75%). May 2019 |
|
 |
Abstract: Mid-air 3D sketching has been mainly explored in Virtual Reality (VR) and typically requires special hardware for motion capture and immersive, stereoscopic displays. The recently developed motion tracking algorithms allow real-time tracking of mobile devices, and have enabled a few mobile applications for 3D sketching in Augmented Reality (AR). However, they are more suitable for making simple drawings only, since they do not consider special challenges with mobile AR 3D sketching, including the lack of stereo display, narrow field of view, and the coupling of 2D input, 3D input and display. To address these issues, we present Mobi3DSketch, which integrates multiple sources of inputs with tools, mainly different versions of 3D snapping and planar/curves surface proxies. Our multimodal interface supports both absolute and relative drawing, allowing easy creation of 3D concept designs in situ. The effectiveness and expressiveness of Mobi3DSketch are demonstrated via a pilot study. |
Qingkun Su*, Xue Bai, Hongbo Fu, Chiew-Lan Tai, and Jue Wang. Live Sketch: Video-driven Dynamic Deformation of Static Drawings. CHI 2018. (Acceptance rate: 26%). April 2018 |
|
 |
Abstract: Creating sketch animations using traditional tools requires special artistic skills, and is tedious even for trained professionals. To lower the barrier for creating sketch animations, we propose a new system, Live Sketch, which allows novice users to interactively bring static drawings to life by applying deformation-based animation effects that are extracted from video examples. Dynamic deformation is first extracted as a sparse set of moving control points from videos and then transferred to a static drawing. Our system addresses a few major technical challenges, such as motion extraction from video, video-to-sketch alignment, and many-to-one motion driven sketch animation. While each of the sub-problems could be difficult to solve fully automatically, we present reliable solutions by combining new computational algorithms with intuitive user interactions. Our pilot study shows that our system allows both users with or without animation skills to easily add dynamic deformation to static drawings. |
Pui Chung Wong*, Kening Zhu, and Hongbo Fu. FingerT9: Leveraging thumb-to-finger interaction for same-side-hand text entry on smartwatches. CHI 2018. (Acceptance rate: 26%). April 2018. |
|
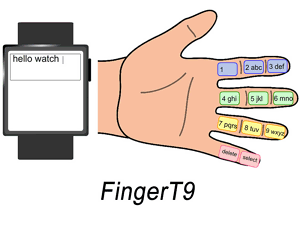 |
Abstract: We introduce FingerT9, leveraging the action of thumb-to-finger touching on the finger segments, to support same-side-hand (SSH) text entry on smartwatches. This is achieved by mapping a T9 keyboard layout to the finger segments. Our solution avoids the problems of fat finger and screen occlusion, and enables text entry using the same-side hand which wears the watch. In the pilot study, we determined the layout mapping preferred by the users. We conducted an experiment to compare the text-entry performances of FingerT9, the tilt-based SSH input, and the direct-touch non-SSH input. The results showed that the participants performed significantly faster and more accurately with FingerT9 than the tilt-based method. There was no significant difference between FingerT9 and direct-touch methods in terms of efficiency and error rate. We then conducted the second experiment to study the learning curve on SSH text entry methods: FingerT9 and the tilt-based input. FingerT9 gave significantly better long-term improvement. In addition, eyes-free text entry (i.e., looking at the screen output but not the keyboard layout mapped on the finger segments) was made possible once the participants were familiar with the keyboard layout. |
Qiang Fu*, Xiaowu Chen, Xiaotian Wang, Sijia Wen, Bin Zhou, and Hongbo Fu. Adaptive Synthesis of Indoor Scenes via Activity-Associated Object Relation Graphs. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH Asia 2017. November 2017. (Acceptance rate: 25.2%) |
|
 |
Abstract: We present a system for adaptive synthesis of indoor scenes given an empty room and only a few object categories. Automatically suggesting indoor objects and proper layouts to convert an empty room to a 3D scene is challenging, since it requires interior design knowledge to balance the factors like space, path distance, illumination and object relations, in order to insure the functional plausibility of the synthesized scenes. We exploit a database of 2D floor plans to extract object relations and provide layout examples for scene synthesis. With the labeled human positions and directions in each plan, we detect the activity relations and compute the coexistence frequency of object pairs to construct activity-aware object relation graphs. Given the input room and user-specified object categories, our system first leverages the object relation graphs and the database floor plans to suggest more potential object categories beyond the specified ones to make resulting scenes functionally complete, and then uses the similar plan references to create the layout of synthesized scenes. We show various synthesis results to demonstrate the practicability of our system, and validate its usability via a user study. We also compare our system with the state-of-the-art furniture layout and activity-centric scene representation methods, in terms of functional plausibility and user friendliness. |
Yuwei Li, Xin Luo, Youyi Zheng, Pengfei Xu, and Hongbo Fu. SweepCanvas: Sketch-based 3D prototyping on an RGB-D image. UIST 2017. Quebec City, Canada, Oct, 2017. |
|
 |
Abstract: The creation of 3D contents still remains one of the most crucial problems for the emerging applications such as 3D printing and Augmented Reality. In Augmented Reality, how to create virtual contents that seamlessly overlay with the real environment is a key problem for human-computer interaction and many subsequent applications. In this paper, we present a sketch-based interactive tool, which we term SweepCanvas, for rapid exploratory 3D modeling on top of an RGBD image. Our aim is to offer end-users a simple yet efficient way to quickly create 3D models on an image. We develop a novel sketch-based modeling interface, which takes a pair of user strokes as input and instantly generates a curved 3D surface by sweeping one stroke along the other. A key enabler of our system is an optimization procedure that extracts pairs of spatial planes from the context to position and sweep the strokes. We demonstrate the effectiveness and power of our modeling system on various RGB-D data sets and validate the use cases via a pilot study.. |
Pengfei Xu*, Hongbo Fu, Chiew-Lan Tai, and Takeo Igarashi. GACA: Group-aware command-based arrangement of graphic elements. CHI 2015. Seoul, April, 2015. |
|
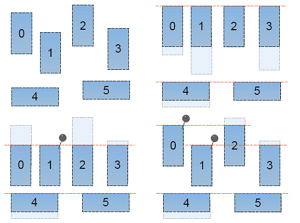 |
Abstract: Many graphic applications rely on command-based arrangement tools to achieve precise layouts. Traditional tools are designed to operate on a single group of elements that are distributed consistently with the arrangement axis implied by a command. This often demands a process with repeated element selections and arrangement commands to achieve 2D layouts involving multiple rows and/or columns of well aligned and/or distributed elements. Our work aims to reduce the numbers of selection operation and command invocation, since such reductions are particularly beneficial to professional designers who design lots of layouts. Our key idea is that an issued arrangement command is in fact very informative, instructing how to automatically decompose a 2D layout into multiple 1D groups, each of which is compatible with the command. We present a parameter-free, command-driven grouping approach so that users can easily predict our grouping results. We also design a simple user interface with pushpins to enable explicit control of grouping and arrangement. Our user study confirms the intuitiveness of our technique and its performance improvement over traditional command-based arrangement tools. |
Pengfei Xu*, Hongbo Fu, Takeo Igarashi, and Chiew-Lan Tai. Global beautification of layouts with interactive ambiguity resolution. UIST 2014. Hawaii, Octobor, 2014. |
|
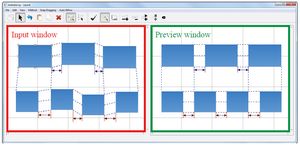 |
Abstract: Automatic global beautification methods have been proposed for sketch-based interfaces, but they can lead to undesired results due to ambiguity in the user’s input. To facilitate ambiguity resolution in layout beautification, we present a novel user interface for visualizing and editing inferred relationships. First, our interface provides a preview of the beautified layout with inferred constraints, without directly modifying the input layout. In this way, the user can easily keep refining beautification results by interactively repositioning and/or resizing elements in the input layout. Second, we present a gestural interface for editing automatically inferred constraints by directly interacting with the visualized constraints via simple gestures. Our efficient implementation of the beautification system provides the user instant feedback. Our user studies validate that our tool is capable of creating, editing and refining layouts of graphic elements and is significantly faster than the standard snap-dragging and command-based alignment tools. |
Zhe Huang, Hongbo Fu, and Rynson W. H. Lau. Data-driven segmentation and labeling of freehand sketches. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH Asia 2014. December 2014. (Acceptance rate: 19.6%) |
|
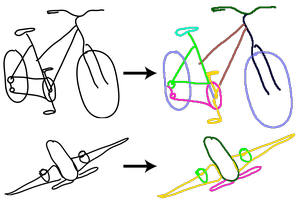 |
Abstract: We present a data-driven approach to derive part-level segmentation and labeling of free-hand sketches, which depict single objects with multiple parts. Our method performs segmentation and labeling simultaneously, by inferring a structure that best fits the input sketch, through selecting and connecting 3D components in the database. The problem is formulated using Mixed Integer Programming, which optimizes over both the local fitness of the selected components and the global plausibility of the connected structure. Evaluations show that our algorithm is significantly better than the straightforward approaches based on direct retrieval or part assembly, and can effectively handle challenging variations in the sketch. |
Qingkun Su*, Wing Ho Andy Li*, Jue Wang and Hongbo Fu. EZ-Sketching: three-level optimization for error-tolerant image tracing. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH 2014. 32(4). Article No. 54. August 2014. (Acceptance rate: 25.1%) |
|
 |
Abstract: We present a new image-guided drawing interface called EZ-Sketching, which uses a tracing paradigm and automatically corrects sketch lines roughly traced over an image by analyzing and utilizing the image features being traced. While previous edge snapping methods aim at optimizing individual strokes, we show that a co-analysis of multiple roughly placed nearby strokes better captures the user's intent. We formulate automatic sketch improvement as a three-level optimization problem and present an efficient solution to it. EZ-Sketching can tolerate errors from various sources such as indirect control and inherently inaccurate input, and works well for sketching on touch devices with small screens using fingers. Our user study confirms that the drawings our approach helped generate show closer resemblance to the traced images, and are often aesthetically more pleasing. |
Kun Xu, Kang Chen, Hongbo Fu, Wei-Lun Sun, and Shi-Min Hu. Sketch2Scene: Sketch-based co-retrieval and co-placement of 3D models. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH 2013. 32(4). Article No. 123. July 2013. (Acceptance rate: 24%) |
|
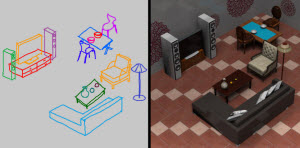 |
Abstract: This work presents Sketch2Scene, a framework that automatically turns a freehand sketch drawing inferring multiple scene objects to semantically valid, well arranged scenes of 3D models. Unlike the existing works on sketch-based search and composition of 3D models, which typically process individual sketched objects one by one, our technique performs co-retrieval and co-placement of 3D relevant models by jointly processing the sketched objects. This is enabled by summarizing functional and spatial relationships among models in a large collection of 3D scenes as structural groups. Our technique greatly reduces the amount of user intervention needed for sketch-based modeling of 3D scenes and fits well into the traditional production pipeline involving concept design followed by 3D modeling. A user study indicates that the 3D scenes automatically synthesized by our technique in seconds are comparable to those manually created by an artist in hours in terms of visual aesthetics. |
Pengfei Xu*, Hongbo Fu, Oscar Kin-Chung Au, and Chiew-Lan Tai. Lazy Selection: a scribble-based tool for smart shape elements selection. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH Asia 2012. 31(6). Article No. 136. December 2012. (Acceptance rate: 24%) |
|
 |
Abstract: This paper presents Lazy Selection, a scribble-based tool for quick selection of one or more desired shape elements by roughly stroking through the elements. Our algorithm automatically refines the selection and reveals the user's intention. To give the user maximum flexibility but least ambiguity, our technique first extracts selection candidates from the scribble-covered elements by examining the underlying patterns and then ranks them based on their location and shape with respect to the user-sketched scribble. Such a design makes our tool tolerant to imprecise input systems and applicable to touch systems without suffering from the fat finger problem. A preliminary evaluation shows that compared to the standard click and lasso selection tools, which are the most commonly used, our technique provides significant improvements in efficiency and flexibility for many selection scenarios. |
Chao-Hui Shen, Hongbo Fu, Kang Chen, and Shi-Min Hu. Strcuture recovery by part assembly. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH Asia 2012. 31(6). Article No. 172. December 2012. (Acceptance rate: 24%) |
|
 |
Abstract: This paper presents a technique that allows quick conversion of acquired low-quality data from consumer-level scanning devices to high-quality 3D models with labeled semantic parts and meanwhile their assembly reasonably close to the underlying geometry. This is achieved by a novel structure recovery approach that is essentially local to global and bottom up, enabling the creation of new structures by assembling existing labeled parts with respect to the acquired data. We demonstrate that using only a small-scale shape repository, our part assembly approach is able to faithfully recover a variety of high-level structures from only a single-view scan of man-made objects acquired by the Kinect system, containing a highly noisy, incomplete 3D point cloud and a corresponding RGB image. |
Hongbo Fu, Shizhe Zhou*, Ligang Liu, and Niloy J. Mitra. Animated construction of line drawings. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH Asia 2011. 30(6). Article No. 133. December 2011. (Acceptance rate: 20.6%) |
|
 |
Abstract: Revealing the sketching sequence of a line drawing can be visually intriguing and used for video-based storytelling. Typically this is enabled based on tedious recording of artists' drawing process. We demonstrate that
it is often possible to estimate a reasonable drawing order from a static line drawing with clearly defined shape geometry,
which looks plausible to a human viewer. We map the key principles of drawing order from drawing cognition to computational procedures in our framework. Our system produces plausible animated constructions
of input line drawings, with no or little user intervention. We test our algorithm on a
range of input sketches, with varying degree of complexity and structure, and evaluate the results via a user study. We also present applications to gesture drawing synthesis and
drawing animation creation especially in the context of video scribing. |
Chao-Hui Shen, Shi-Sheng Huang, Hongbo Fu, and Shi-Min Hu. Adaptive partitioning of urban facades. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH Asia 2011. 30(6). Article No. 184. December 2011. (Acceptance rate: 20.6%). One of the nine highlights among all SIGGRAPH Asia 2011 papers |
|
 |
Abstract: Automatically discovering high-level facade structures in unorganized 3D point clouds of
urban scenes is crucial for gigantic applications like digitalization of real cities. However, this problem is challenging due to poor-quality input data, contaminated with severe missing areas, noise and outliers. This work introduces the concept of adaptive partitioning to automatically derive a flexible and hierarchical representation of 3D urban facades. Our key observation is that urban facades are largely governed by concatenated and/or interlaced grids. Hence, unlike previous automatic facade analysis works which are restricted to globally rectilinear grids, we propose to automatically partition the facade in an adaptive manner,
in which the splitting direction, the number and location of splitting planes are all adaptively determined. Such an adaptive partition operation is performed recursively to generate a hierarchical representation of the facade. We show that the concept of adaptive partitioning is also applicable to
flexible and robust analysis of image facades. We evaluate our method on a dozen of LiDAR scans of various complexity and styles and the eTRIMS image database with 60 facade images. A series of applications that benefit from our approach are also demonstrated. |
Shizhe Zhou, Hongbo Fu, Ligang Liu, Daniel Cohen-Or, and Xiaoguang Han. Parametric reshaping of human bodies in images. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH 2010. 29(4). Article No. 126. July 2010. (Acceptance rate: 26%). One of the six highlights among all SIGGRAPH 2010 papers |
|
 |
Abstract: We present an easy-to-use image retouching technique for realistic reshaping of human bodies in a single image. A model-based approach is taken by integrating a 3D whole-body morphable model into the reshaping process to achieve globally consistent editing effects. A novel body-aware image warping approach is introduced to reliably transfer the reshaping effects from the model to the image, even under moderate fitting errors. Thanks to the parametric nature of the model, our technique parameterizes the degree of reshaping by a small set of semantic attributes, such as weight and height. It allows easy creation of desired reshaping effects by changing the full-body attributes, while producing visually pleasing results even for loosely-dressed humans in casual photographs with a variety of poses and shapes. |
Yu-Shuen Wang, Hongbo Fu, Olga Sorkine, Tong-Yee Lee, and Hans-Peter Seidel. Motion-aware temporal coherence for video resizing. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH Asia 2009. 28(5). Article No. 127. December 2009. (Acceptance rate: 25%) |
|
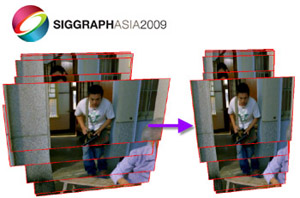 |
Abstract: Temporal coherence is crucial in content-aware video retargeting.
To date, this problem has been addressed by constraining temporally adjacent pixels to be transformed coherently. However, due to the motion-oblivious nature of this simple constraint,
the retargeted videos often exhibit flickering and waving artifacts, especially when significant camera or object motions are involved.
Since the feature correspondence across frames changes spatially with both camera and object motion, motion-aware treatment of features is required for video resizing.
This motivated us to align consecutive frames by estimating interframe camera motion and to constrain relative positions in the aligned frames. To preserve object motion, we detect distinct moving areas of objects across multiple frames and constrain each of them to be resized consistently. We build a complete video resizing framework by incorporating our motion-aware constraints with an adaptation of the scale-and-stretch optimization recently proposed by Wang and colleagues. Our streaming implementation of the framework allows efficient resizing of long video sequences with low memory cost.
Experiments demonstrate that our method produces spatiotemporally coherent retargeting results even for challenging examples with complex camera and object motion, which are difficult to handle with previous techniques. |
Hongbo Fu, Daniel Cohen-Or, Gideon Dror, and Alla Sheffer. Upright orientation of man-made objects. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH 2008. 27(3). Article No. 42. August 2008. (Acceptance rate: 17.9%) |
|
 |
Abstract: Humans
usually associate an upright orientation with objects, placing them in
a way that they are most commonly seen in our surroundings. While it is
an open challenge to recover the functionality of a shape from its
geometry alone, this paper shows that it is often possible to infer its
upright orientation by analyzing its geometry. Our key idea is to
reduce the two-dimensional (spherical) orientation space to a small set
of orientation candidates using functionality-related geometric
properties of the object, and then determine the best orientation using
an assessment function of several functional geometric attributes
defined with respect to each candidate. Specifically we focus on
obtaining the upright orientation for man-made objects that typically
stand on some flat surface (ground, floor, table, etc.), which include
the vast majority of objects in our everyday surroundings. For these
types of models orientation candidates can be defined according to
static equilibrium. For each candidate, we introduce a set of
discriminative attributes linking shape to function. We learn an
assessment function of these attributes from a training set using a
combination of Random Forest classifier and Support Vector Machine
classifier. Experiments demonstrate that our method generalizes well
and achieves about 90% prediction accuracy for both a 10-fold
cross-validation over the training set and a validation with an
independent test set. |
Oscar
Kin-Chung Au, Hongbo Fu, Chiew-Lan
Tai, and Daniel Cohen-Or. Handle-aware isolines for scalable shape
editing. ACM Transactions on Graphics (TOG) special issue: Proceedings of ACM SIGGRAPH 2007. 26(3). Aricle No. 83. July 2007. (Acceptance rate: 23.7%) [citation] |
|
 |
Abstract: Handle-based mesh deformation is essentially
a nonlinear problem. To allow scalability, the original deformation
problem can be approximately represented by a compact set of control
variables. We show the direct relation between the locations of handles
on the mesh and the local rigidity under deformation, and introduce the
notion of handle-aware
rigidity. Then, we present a
reduced model whose control variables are intelligently distributed
across the surface, respecting the rigidity information and the
geometry. Specifically, for each handle, the control variables are the
transformations of the isolines of a harmonic scalar field representing
the deformation propagation from that handle. The isolines constitute a
virtual skeletal structure similar to the bones in skinning
deformation, thus correctly capturing the low-frequency shape
deformation. To interpolate the transformations from the isolines to
the original mesh, we design a method which is local, linear and
geometry-dependent. This novel interpolation scheme and the
transformation-based reduced domain allow each iteration of the
nonlinear solver to be fully computed over the reduced domain. This
makes the per-iteration cost dependent on only the number of isolines
and enables compelling deformation of highly detailed shapes at
interactive rates. In addition, we show how the handle-driven isolines
provide an efficient means for deformation transfer without full shape
correspondence. |
Jiaye Leng*, Hui Ye*, Pengfei Xu, Miu-Ling Lam, and Hongbo Fu. GenFODrawing: Supporting Creative
Found Object Drawing with Generative AI. IEEE
Transactions on Visualization and Computer Graphics (TVCG). Accepted for publication. |
|
|
Abstract: Found object drawing is a creative art form incorporating everyday objects into imaginative images, offering a refreshing and unique way to express ideas. However, for many people, creating this type of work can be challenging due to difficulties in generating creative ideas and finding suitable reference images to help translate their ideas onto paper. Based on the findings of a formative study, we propose GenFODrawing, a creativity support tool to help users create diverse found object drawings. Our system provides AI-driven textual and visual inspirations, and enhances controllability through sketch-based and box-conditioned image generation, enabling users to create personalized outputs. We conducted a user study with twelve participants to compare GenFODrawing to a baseline condition where the participants completed the creative tasks using their own desired approaches without access to our system. The study demonstrated that GenFODrawing enabled easier exploration of diverse ideas, greater agency and control through the creative process, and higher creativity support compared to the baseline. A further open-ended study demonstrated the system's usability and expressiveness, and all participants found the creative process engaging.
|
Ying Jiang, Pengfei Xu, Congyi Zhang, Hongbo Fu, Henry Y K Lau, and Wenping Wang. Region-aware Color Smudging. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 31(4): 1999 - 2011. April 2025. |
|
|
Abstract: Color smudge operations from digital painting software enable users to create natural shading effects in high-fidelity paintings by interactively mixing colors. To precisely control results in traditional painting software, users tend to organize flat-filled color regions in multiple layers and smudge them to generate different color gradients. However, the requirement to carefully deal with regions makes the smudging process time-consuming and laborious, especially for non-professional users. This motivates us to investigate how to infer user-desired smudging effects when users smudge over regions in a single layer. To investigate improving color smudge performance, we first conduct a formative study. Following the findings of this study, we design SmartSmudge, a novel smudge tool that offers users dynamical smudge brushes and real-time region selection for easily generating natural and efficient shading effects. We demonstrate the efficiency and effectiveness of the proposed tool via a user study and quantitative analysis.
|
Chufeng Xiao* and Hongbo Fu. CustomSketching: Sketch Concept Extraction for Sketch-based
Image Synthesis and Editing. Pacific Graphics 2024 (Special Issue of Computer Graphics Forum (CGF)). 43(7). October 2024. |
|
|
Abstract: Personalization techniques for large text-to-image (T2I) models allow users to incorporate new concepts from reference images. However, existing methods primarily rely on textual descriptions, leading to limited control over customized images and failing to support fine-grained and local editing (e.g., shape, pose, and details). In this paper, we identify sketches as an intuitive and versatile representation that can facilitate such control, e.g., contour lines capturing shape information and flow lines representing texture. This motivates us to explore a novel task of sketch concept extraction: given one or more sketch-image pairs, we aim to extract a special sketch concept that bridges the correspondence between the images and sketches, thus enabling sketch-based image synthesis and editing at a fine-grained level. To accomplish this, we introduce CustomSketching, a two-stage framework for extracting novel sketch concepts via few-shot learning. Considering that an object can often be depicted by a contour for general shapes and additional strokes for internal details, we introduce a dual-sketch representation to reduce the inherent ambiguity in sketch depiction. We employ a shape loss and a regularization loss to balance fidelity and editability during optimization. Through extensive experiments, a user study, and several applications, we show our method is effective and superior to the adapted baselines. [Paper] |
Deng Yu*, Chufeng Xiao*, Manfred Lau, and Hongbo Fu. Sketch2Stress: Sketching with Structural Stress Awareness. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 30(10): 6851 - 6865. Oct. 2024. |
|
|
Abstract: In the process of product design and digital fabrication, the structural analysis of a designed prototype is a fundamental and essential step. However, such a step is usually invisible or inaccessible to designers at the early sketching phase. This limits the user’s ability to consider a shape’s physical properties and structural soundness. To bridge this gap, we introduce a novel approach Sketch2Stress that allows users to perform structural analysis of desired objects at the sketching stage. This method takes as input a 2D freehand sketch and one or multiple locations of user-assigned external forces. With the specially-designed two-branch generative-adversarial framework, it automatically predicts a normal map and a corresponding structural stress map distributed over the user-sketched underlying object. In this way, our method empowers designers to easily examine the stress sustained everywhere and identify potential problematic regions of their sketched object. Furthermore, combined with the predicted normal map, users are able to conduct a region-wise structural analysis efficiently by aggregating the stress effects of multiple forces in the same direction. Finally, we demonstrate the effectiveness and practicality of our system with extensive experiments and user studies. [Paper] |
Deng Yu*, Manfred Lau, Lin Gao, and Hongbo Fu. Sketch Beautification: Learning Part Beautification and Structure Refinement for Sketches of Man-made Objects. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 30(9): 6533 - 6546. Sep. 2024. |
|
|
Abstract: We present a novel freehand sketch beautification method, which takes as input a freely drawn sketch of a man-made object and automatically beautifies it both geometrically and structurally. Beautifying a sketch is challenging because of its highly abstract and heavily diverse drawing manner. Existing methods are usually confined to their limited training samples and thus cannot beautify freely drawn sketches with both geometric and structural variations. To address this challenge, we adopt a divide-and-combine strategy. Specifically, we first parse an input sketch into semantic components, beautify individual components by a learned part beautification module based on part-level implicit manifolds, and then reassemble the beautified components through a structure beautification module. With this strategy, our method can go beyond the training samples and handle novel freehand sketches. We demonstrate the effectiveness of our system with extensive experiments and a perceptual study. [Paper] |
Zhaoyang Zhang, Junliang Chen, Hongbo Fu, Jianjun Zhao, Shu-Yu Chen, and Lin Gao. Text2Face: Text-based Face Generation with Geometry and Appearance Control. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 30(9): 6481 - 6492. Sep. 2024. |
|
Abstract: Recent years have witnessed the emergence of various techniques proposed for text-based human face generation and manipulation. Such methods, targeting bridging the semantic gap between text and visual contents, provide users with a deft hand to turn ideas into visuals via text interface and enable more diversified multimedia applications. However, due to the flexibility of linguistic expressiveness, the mapping from sentences to desired facial images is clearly many-to-many, causing ambiguities during text-to-face generation. To alleviate these ambiguities, we introduce a local-to-global framework with two graph neural networks (one for geometry and the other for appearance) embedded to model the inter-dependency among facial parts. This is based upon our key observation that the geometry and appearance attributes among different facial components are not mutually independent, i.e., the combinations of part-level facial features are not arbitrary and thus do not conform to a uniform distribution. By learning from the dataset distribution and enabling recommendations given partial descriptions of human faces, these networks are highly suitable for our text-to-face task. Our method is capable of generating high-quality attribute-conditioned facial images from text. Extensive experiments have confirmed the superiority and usability of our method over the prior art. [Paper] |
Zhongjin Luo, Dong Du, Heming Zhu, Yizhou Yu, Hongbo Fu, and Xiaoguang Han. SketchMetaFace: A Learning-based Sketching Interface for Free-style and High-fidelity 3D Character Face Modeling. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 30(8): 5260 - 5275. August 2024. |
|
|
Abstract: Modeling 3D avatars benefits various application scenarios such as AR/VR, gaming, and filming. Character faces contribute significant diversity and vividity as a vital component of avatars. However, building 3D character face models usually requires a heavy workload with commercial tools, even for experienced artists. Various existing sketch-based tools fail to support amateurs in modeling diverse facial shapes and rich geometric details. In this paper, we present SketchMetaFace - a sketching system targeting amateur users to model free-style and high-fidelity 3D faces in minutes. We carefully design both the user interface and the underlying algorithm. First, curvature-aware strokes are introduced to better support the controllability of detail carving. Second, considering the key problem of mapping a 2D sketch map to a 3D model, we develop a novel learning-based method termed “Implicit and Depth Guided Mesh Modeling” (IDGMM). It combines the advantages of mesh, implicit, and depth representations to achieve high-quality results with high efficiency. In addition, to further support usability, we present a coarse-to-fine interface design and a data-driven stroke suggestion tool. User studies demonstrate the superiority of our system over existing modeling tools in terms of the ease to use and visual quality of results. Experimental analyses also show that IDGMM reaches a better trade-off between accuracy and efficiency. |
Shao-Kui Zhang, Hou Tam, Yike Li, Ke-Xin Ren, Hongbo Fu, and Song-Hai Zhang. SceneDirector: Interactive Scene Synthesis by Simultaneously Editing Multiple Objects in Real-Time. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 30(8): 4558 - 4569. August 2024. |
|
|
Abstract: Intelligent tools for creating synthetic scenes have been developed significantly in recent years. Existing techniques on interactive scene synthesis only incorporate a single object at every interaction, i.e., crafting a scene through a sequence of single-object insertions with user preferences. These techniques suggest objects by considering existent objects in the scene instead of fully picturing the eventual result, which is inherently problematic since the sets of objects to be inserted are seldom fixed during interactive processes. In this paper, we introduce SceneDirector, a novel interactive scene synthesis tool to help users quickly picture various potential synthesis results by simultaneously editing groups of objects. Specifically, groups of objects are rearranged in real-time with respect to a position of an object specified by a mouse cursor or gesture, i.e., a movement of a single object would trigger the rearrangement of the existing object group, the insertions of potentially appropriate objects, and the removal of redundant objects. To achieve this, we first propose an idea of coherent group set which expresses various concepts of layout strategies. Subsequently, we present layout attributes, where users can adjust how objects are arranged by tuning the weights of the attributes. Thus, our method gives users intuitive control of both how to arrange groups of objects and where to place them. Through extensive experiments and two applications, we demonstrate the potentiality of our framework and how it enables concurrently effective and efficient interactions of editing groups of objects. |
Qiang Fu, Shuhan He, Xueming Li, and Hongbo Fu. PlanNet: A Generative Model for Component-Based Plan Synthesis. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 30(8): 4739 - 4751. August 2024. |
|
|
Abstract: We propose a novel generative model named as PlanNet for component-based plan synthesis. The proposed model consists of three modules, a wave function collapse algorithm to create large-scale wireframe patterns as the embryonic forms of floor plans, and two deep neural networks to outline the plausible boundary from each squared pattern, and meanwhile estimate the potential semantic labels for the components. In this manner, we use PlanNet to generate a large-scale component-based plan dataset with 10 K examples. Given an input boundary, our method retrieves dataset plan examples with similar configurations to the input, and then transfers the space layout from a user-selected plan example to the input. Benefiting from our interactive workflow, users can recursively subdivide individual components of the plans to enrich the plan contents, thus designing more complex plans for larger scenes. Moreover, our method also adopts a random selection algorithm to make the variations on semantic labels of the plan components, aiming at enriching the 3D scenes that the output plans are suited for. To demonstrate the quality and versatility of our generative model, we conduct intensive experiments, including the analysis of plan examples and their evaluations, plan synthesis with both hard and soft boundary constraints, and 3D scenes designed with the plan subdivision on different scales. We also compare our results with the state-of-the-art floor plan synthesis methods to validate the feasibility and efficacy of the proposed generative model. |
Qiang Fu, Fan Zhang, Xueming Li, and Hongbo Fu. Magic Furniture: Design Paradigm of Multi-function Assembly. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 30(7): 4068 - 4079. July 2024. |
|
|
Abstract: Assembly-based furniture with movable parts enables shape and structure reconfiguration, thus supporting multiple functions. Although a few attempts have been made for facilitating the creation of multi-function objects, designing such a multi-function assembly with the existing solutions often requires high imagination of designers. We develop the Magic Furniture system for users to easily create such designs simply given multiple cross-category objects. Our system automatically leverages the given objects as references to generate a 3D model with movable boards driven by back-and-forth movement mechanisms. By controlling the states of these mechanisms, a designed multi-function furniture object can be reconfigured to approximate the shapes and functions of the given objects. To ensure the designed furniture easy to transform between different functions, we perform an optimization algorithm to choose a proper number of movable boards and determine their shapes and sizes, following a set of design guidelines. We demonstrate the effectiveness of our system through various multi-function furniture designed with different sets of reference inputs and various movement constraints. We also evaluate the design results through several experiments including comparative and user studies. |
Xinjie Wang, Qingxuan Lv, Guo Chen, Jing Zhang, Zhiqiang Wei, Junyu Dong, Hongbo Fu, Zhipeng Zhu, Jingxin Liu, and Xiaogang Jin. MobileSky: Real-time Sky Replacement for Mobile AR. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 30(7): 4304 - 4320. July 2024. |
|
|
Abstract: We present MobileSky, the first automatic method for real-time high-quality sky replacement for mobile AR applications. The primary challenge of this task is how to extract sky regions in camera feed both quickly and accurately. While the problem of sky replacement is not new, previous methods mainly concern extraction quality rather than efficiency, limiting their application to our task. We aim to provide higher quality, both spatially and temporally consistent sky mask maps for all camera frames in real time. To this end, we develop a novel framework that combines a new deep semantic network called FSNet with novel post-processing refinement steps. By leveraging IMU data, we also propose new sky-aware constraints such as temporal consistency, position consistency, and color consistency to help refine the weakly classified part of the segmentation output. Experiments show that our method achieves an average of around 30 FPS on off-the-shelf smartphones and outperforms the state-of-the-art sky replacement methods in terms of execution speed and quality. In the meantime, our mask maps appear to be visually more stable across frames. Our fast sky replacement method enables several applications, such as AR advertising, art making, generating fantasy celestial objects, visually learning about weather phenomena, and advanced video-based visual effects. To facilitate future research, we also create a new video dataset containing annotated sky regions with IMU data. |
Xian Wu, Chen Wang, Hongbo Fu, Ariel Shamir, and Song-Hai Zhang. DeepPortraitDrawing: Generating Human Body Images from Freehand Sketches. CAD/Graphics 2023 (Special Issue of Computers & Graphics). 116: 73-81. Nov. 2023. |
|
|
Abstract: Various methods for generating realistic images of objects and human faces from freehand sketches have been explored. However, generating realistic human body images from sketches is still a challenging problem. It is, first because of the sensitivity to human shapes, second because of the complexity of human images caused by body shape and pose changes, and third because of the domain gap between realistic images and freehand sketches. In this work, we present DeepPortraitDrawing, a deep generative framework for converting roughly drawn sketches to realistic human body images. To encode complicated body shapes under various poses, we take a local-to-global approach. Locally, we employ semantic part auto-encoders to construct part-level shape spaces, which are useful for refining the geometry of an input pre-segmented hand-drawn sketch. Globally, we employ a cascaded spatial transformer network to refine the structure of body parts by adjusting their spatial locations and relative proportions. Finally, we use a style-based generator as the global synthesis network for the sketch-to-image translation task which is modulated by segmentation maps for semantic preservation. Extensive experiments have shown that given roughly sketched human portraits, our method produces more realistic images than the state-of-the-art sketch-to-image synthesis techniques. [Paper] |
Jie Zhou*, Zhongjin Luo, Qian Yu, Xiaoguang Han, and Hongbo Fu. GA-Sketching: Shape Modeling from Multi-View Sketching with Geometry-Aligned Deep Implicit Functions. Pacific Graphics 2023 (Special Issue of Computer Graphics Forum (CGF)). 42(7). October 10-13, 2023. |
|
|
Abstract: Sketch-based shape modeling aims to bridge the gap between 2D drawing and 3D modeling by providing an intuitive and accessible approach to create 3D shapes from 2D sketches. However, existing methods still suffer from limitations in reconstruction quality and multi-view interaction friendliness, hindering their practical application. This paper proposes a faithful and user-friendly iterative solution to tackle these limitations by learning geometry-aligned deep implicit functions from one or multiple sketches. Our method lifts 2D sketches to volume-based feature tensors, which align strongly with the output 3D shape, enabling accurate reconstruction and faithful editing. Such a geometry-aligned feature encoding technique is well-suited to iterative modeling since features from different viewpoints can be easily memorized or aggregated. Based on these advantages, we design a unified interactive system for sketch-based shape modeling. It enables users to generate the desired geometry iteratively by drawing sketches from any number of viewpoints. In addition, it allows users to edit the generated surface by making a few local modifications. We demonstrate the effectiveness and practicality of our method with extensive experiments and user studies, where we found that our method outperformed existing methods in terms of accuracy, efficiency, and user satisfaction. |
Bin Bao and and Hongbo Fu. Line Drawing Vectorization via Coarse-to-Fine Curve Network Optimization. Computer Graphics Forum (CGF). 42(6). September 2023. |
|
|
Abstract: Vectorizing line drawings is a fundamental component of the workflow in various applications such as graphic design and computer animation. A practical vectorization tool is desired to produce high-quality curves that are faithful to the original inputs and close to the connectivity of human drawings. The existing line vectorization approaches either suffer from low geometry accuracy or incorrect connectivity for noisy inputs or detailed complex drawings.We propose a novel line drawing vectorization framework based on coarse-to-fine curve network optimization. Our technique starts with an initial curve network generated by an existing tracing method. It then performs a global optimization which fits the curve network to image centerlines. Finally, our method performs a finer optimization in local junction regions to achieve better connectivity and curve geometry around junctions. We qualitatively and quantitatively evaluate our system on line drawings with varying image quality and shape complexity, and show that our technique outperforms existing works in terms of curve quality and computational time. Remark: The timing of [Bessmeltsev and Solomon 2019] in our paper is based on the publicly released code of [Bessmeltsev and Solomon 2019] compiled in a Mac environment. However, after the acceptance of this paper, we realized that the authors of [Bessmeltsev and Solomon 2019] tested their code in a Windows environment only and the performance of their code compiled in a Windows environment might be significantly boosted. For a fairer comparison, please contact Mikhail Bessmeltsev for a Windows binary version. [Paper] |
Yilan Chen*, Kin Chung Kwan*, and Hongbo Fu. Autocompletion of Repetitive Stroking with Image Guidance. Computational Visual Media (CVM). 9: 581-596. March 2023. |
|
Abstract: Image-guided drawing can compensate for a lack of skill but often requires a significant number of repetitive strokes to create textures. Existing automatic stroke synthesis methods are usually limited to predefined styles or require indirect manipulation that may break the spontaneous flow of drawing. We present an assisted drawing system to autocomplete repetitive short strokes during a user’s normal drawing process. Users draw over a reference image as usual; at the same time, our system silently analyzes the input strokes and the reference to infer strokes that follow the user’s input style when certain repetition is detected. Users can accept, modify, or ignore the system’s predictions and continue drawing, thus maintaining fluid control over drawing. Our key idea is to jointly analyze image regions and user input history to detect and predict repetition. The proposed system can effectively reduce the user’s workload when drawing repetitive short strokes, helping users to create results with rich patterns. |
Linzi Qu*, Jiaxiang Shang, Xiaoguang Han, and Hongbo Fu. ReenactArtFace: Artistic Face Image Reenactment. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 30(7): 4080 - 4092. July 2024. |
|
|
Abstract: Large-scale datasets and deep generative models have enabled impressive progress in human face reenactment. Existing solutions for face reenactment have focused on processing real face images through facial landmarks by generative models. Different from real human faces, artistic human faces (e.g., those in paintings, cartoons, etc.) often involve exaggerated shapes and various textures. Therefore, directly applying existing solutions to artistic faces often fails to preserve the characteristics of the original artistic faces (e.g., face identity and decorative lines along face contours) due to the domain gap between real and artistic faces. To address these issues, we present ReenactArtFace, the first effective solution for transferring the poses and expressions from human videos to various artistic face images. We achieve artistic face reenactment in a coarse-to-fine manner. First, we perform 3D artistic face reconstruction, which reconstructs a textured 3D artistic face through a 3D morphable model (3DMM) and a 2D parsing map from an input artistic image. The 3DMM can not only rig the expressions better than facial landmarks but also render images under different poses/expressions as coarse reenactment results robustly. However, these coarse results suffer from self-occlusions and lack contour lines. Second, we thus perform artistic face refinement by using a personalized conditional adversarial generative model (cGAN) fine-tuned on the input artistic image and the coarse reenactment results. For high-quality refinement, we propose a contour loss to supervise the cGAN to faithfully synthesize contour lines. Quantitative and qualitative experiments demonstrate that our method achieves better results than the existing solutions. |
Beijia Chen, Yuefan Shen, Hongbo Fu, Xiang Chen, Kun Zhou, and Youyi Zheng. NeuralReshaper: Single-image Human-body Retouching with Deep Neural Networks. Science China - Information Sciences. Accepted for publication. |
|
|
Abstract: In this paper, we present NeuralReshaper, a novel method for semantic reshaping of human bodies in single images using deep generative networks. To achieve globally coherent reshaping effects, our approach follows a fit-then-reshape pipeline, which first fits a parametric 3D human model to a source human image and then reshapes the fitted 3D model with respect to user-specified semantic attributes. Previous methods rely on image warping to transfer 3D reshaping effects to the entire image domain and thus often cause distortions in both foreground and background. In contrast, we resort to generative adversarial nets conditioned on the source image and a 2D warping field induced by the reshaped 3D model, to achieve more realistic reshaping results. Specifically, we separately encode the foreground and background information in the source image using a two-headed UNet-like generator, and guide the information flow from the foreground branch to the background branch via feature space warping. Furthermore, to deal with the lack-of-data problem that no paired data exist (i.e., the same human bodies in varying shapes), we introduce a novel self-supervised strategy to train our network. Unlike previous methods that often require manual efforts to correct undesirable artifacts caused by incorrect body-to-image fitting, our method is fully automatic. Extensive experiments on both indoor and outdoor datasets demonstrate the superiority of our method over previous approaches. [Paper, Video] |
Zhipeng Yang, Yu-Hui Wen, Shu-Yu Chen, Xiao Liu, Yuan Gao, Yong-Jin Liu, Lin Gao, and Hongbo Fu. Keyframe Control of Music-driven 3D Dance Generation. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 30(7): 3474 - 3486. July 2024. |
|
|
Abstract: For 3D animators, choreography with artificial intelligence has attracted more attention recently. However, most existing deep learning methods mainly rely on music for dance generation and lack sufficient control over generated dance motions. To address this issue, we introduce the idea of keyframe interpolation for music-driven dance generation and present a novel transition generation technique for choreography. Specifically, this technique synthesizes visually diverse and plausible dance motions by using normalizing flows to learn the probability distribution of dance motions conditioned on a piece of music and a sparse set of key poses. Thus, the generated dance motions respect both the input musical beats and the key poses. To achieve a robust transition of varying lengths between the key poses, we introduce a time embedding at each timestep as an additional condition. Extensive experiments show that our model generates more realistic, diverse, and beat-matching dance motions than the compared state-of-the-art methods, both qualitatively and quantitatively. Our experimental results demonstrate the superiority of the keyframe-based control for improving the diversity of the generated dance motions. |
Jingyuan Liu, Nazmus Saquib, Zhutian Chen, Rubaiat Habib Kazi, Li-Yi Wei, Hongbo Fu, Chiew-Lan Tai. PoseCoach: A Customizable Analysis and Visualization System for Video-based Running Coaching. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 30(7): 3474 - 3486. July 2024. |
|
|
Abstract: Videos are an accessible form of media for analyzing sports postures and providing feedback to athletes. Existing sport-specific systems embed bespoke human pose attributes and thus can be hard to scale for new attributes, especially for users without programming experiences. Some systems retain scalability by directly showing the differences between two poses, but they might not clearly visualize the key differences that viewers would like to pursue. Besides, video-based coaching systems often present feedback on the correctness of poses by augmenting videos with visual markers or reference poses. However, previewing and augmenting videos limit the analysis and visualization of human poses due to the fixed viewpoints in videos, which confine the observation of captured human movements and cause ambiguity in the augmented feedback. To address these issues, we study customizable human pose data analysis and visualization in the context of running pose attributes, such as joint angles and step distances. Based on existing literature and a formative study, we have designed and implemented a system, PoseCoach, to provide feedback on running poses for amateurs by comparing the running poses between a novice and an expert. PoseCoach adopts a customizable data analysis model to allow users’ controllability in defining pose attributes of their interests through our interface. To avoid the influence of viewpoint differences and provide intuitive feedback, PoseCoach visualizes the pose differences as part-based 3D animations on a human model to imitate the demonstration of a human coach. We conduct a user study to verify our design components and conduct expert interviews to evaluate the usefulness of the system. |
Yue-Ren Jiang, Shu-Yu Chen (joint first author), Hongbo Fu, and Lin Gao. Identity-aware and Shape-aware Propagation of Face Editing in Videos. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 30(7): 3444 - 3456. July 2024. |
|
|
Abstract: The development of deep generative models has inspired various facial image editing methods, but many of them are difficult to be directly applied to video editing due to various challenges ranging from imposing 3D constraints, preserving identity consistency, ensuring temporal coherence, etc. To address these challenges, we propose a new framework operating on the StyleGAN2 latent space for identity-aware and shape-aware edit propagation on face videos. In order to reduce the difficulties of maintaining the identity, keeping the original 3D motion, and avoiding shape distortions, we disentangle the StyleGAN2 latent vectors of human face video frames to decouple the appearance, shape, expression, and motion from identity. An edit encoding module is used to map a sequence of image frames to continuous latent codes with 3D parametric control and is trained in a self-supervised manner with identity loss and triple shape losses. Our model supports propagation of edits in various forms: I. direct appearance editing on a specific keyframe, II. implicit editing of face shape via a given reference image, and III. existing latent-based semantic edits. Experiments show that our method works well for various forms of videos in the wild and outperforms an animation-based approach and the recent deep generative techniques. |
Yang-Tian Sun, Qian-Cheng Fu, Yue-Ren Jiang, Zitao Liu, Yu-Kun Lai, Hongbo Fu, and Lin Gao. Human Motion Transfer with 3D Constraints and Detail Enhancement. IEEE
Transactions on Pattern Analysis and Machine Intelligence (PAMI). 45(4): 4682 - 4693. April 2023. |
|
|
Abstract: We propose a new method for realistic human motion transfer using a generative adversarial network (GAN), which generates a motion video of a target character imitating actions of a source character, while maintaining high authenticity of the generated results. We tackle the problem by decoupling and recombining the posture information and appearance information of both the source and target characters. The innovation of our approach lies in the use of the projection of a reconstructed 3D human model as the condition of GAN to better maintain the structural integrity of transfer results in different poses. We further introduce a detail enhancement net to enhance the details of transfer results by exploiting the details in real source frames. Extensive experiments show that our approach yields better results both qualitatively and quantitatively than the state-of-the-art methods. |
Zeyu Hu*, Xuyang Bai*, Jiaxiang Shang, Runze Zhang, Jiayu Dong, Xin Wang, Guangyuan Sun, Hongbo Fu, and Chiew-Lan Tai. Voxel-Mesh Network for Geodesic-Aware 3D Semantic Segmentation. IEEE
Transactions on Pattern Analysis and Machine Intelligence (PAMI). 47(5): 3244 - 3256. (This is an extended version of our ICCV 2021 paper) |
|
|
Abstract: In recent years, sparse voxel-based methods have become the state-of-the-arts for 3D semantic segmentation of indoor scenes, thanks to the powerful 3D CNNs. Nevertheless, being oblivious to the underlying geometry, voxel-based methods suffer from ambiguous features on spatially close objects and struggle with handling complex and irregular geometries due to the lack of geodesic information. In view of this, we present Voxel-Mesh Network (VMNet), a novel 3D deep architecture that operates on the voxel and mesh representations leveraging both the Euclidean and geodesic information. Intuitively, the Euclidean information extracted from voxels can offer contextual cues representing interactions between nearby objects, while the geodesic information extracted from meshes can help separate objects that are spatially close but have disconnected surfaces. To incorporate such information from the two domains, we design an intra-domain attentive module for effective feature aggregation and an inter-domain attentive module for adaptive feature fusion. Experimental results validate the effectiveness of VMNet: specifically, on the challenging ScanNet dataset for large-scale segmentation of indoor scenes, it outperforms the state-of-the-art SparseConvNet and MinkowskiNet (74.6% vs 72.5% and 73.6% in mIoU) with a simpler network structure (17M vs 30M and 38M parameters). |
Yu-Hui Wen, Lin Gao, Hongbo Fu, Fang-Lue Zhang, Shihong Xia, and Yong-Jin Liu. Motif-GCNs with Local and Non-Local Temporal Blocks for Skeleton-Based Action Recognition. IEEE
Transactions on Pattern Analysis and Machine Intelligence (PAMI). 45(2): 2009 - 2023. Feb. 2023. |
|
|
Abstract: Recent works have achieved remarkable performance for action recognition with human skeletal data by utilizing graph convolutional models. Existing models mainly focus on developing graph convolutional operations to encode structural properties of the skeletal graph, whose topology is manually predefined and fixed over all action samples. Some recent works further take sample-dependent relationships among joints into consideration. However, the complex relationships between arbitrary pairwise joints are difficult to learn and the temporal features between frames are not fully exploited by simply using traditional convolutions with small local kernels. In this paper, we propose a motif-based graph convolution method, which makes use of sample-dependent latent relations among non-physically connected joints to impose a high-order locality and assigns different semantic roles to physical neighbors of a joint to encode hierarchical structures. Furthermore, we propose a sparsity-promoting loss function to learn a sparse motif adjacency matrix for latent dependencies in non-physical connections. For extracting effective temporal information, we propose an efficient local temporal block. It adopts partial dense connections to reuse temporal features in local time windows, and enrich a variety of information flow by gradient combination. In addition, we introduce a non-local temporal block to capture global dependencies among frames. Our model can capture local and non-local relationships both spatially and temporally, by integrating the local and non-local temporal blocks into the sparse motif-based graph convolutional networks (SMotif-GCNs). Comprehensive experiments on four large-scale datasets show that our model outperforms the state-of-the-art methods. |
Xuanyu Wang*, Hui Ye*, Christian Sandor, Weizhan Zhang, and Hongbo Fu. Predict-and-Drive: Avatar Motion Adaption in Room-Scale Augmented Reality Telepresence with Heterogeneous Spaces. IEEE
Transactions on Visualization and Computer Graphics (TVCG): Special Issue for IEEE ISMAR 2022. 28(11): 3705 - 3714. Nov. 2022. |
|
 |
Abstract: Avatar-mediated symmetric Augmented Reality (AR) telepresence has emerged with the ability to empower users located in different remote spaces to interact with each other in 3D through avatars. However, different spaces have heterogeneous structures and features, which bring difficulties in synchronizing avatar motions with real user motions and adapting avatar motions to local scenes. To overcome these issues, existing methods generate mutual movable spaces or retarget the placement of avatars. However, these methods limit the telepresence experience in a small sub-area space, fix the positions of users and avatars, or adjust the beginning/ending positions of avatars without presenting smooth transitions. Moreover, the delay between the avatar retargeting and users’ real transitions can break the semantic synchronization between users’ verbal conversation and perceived avatar motion. In this paper, we first examine the impact of the aforementioned transition delay and explore the preferred transition style with the existence of such delay through user studies. With the results showing a significant negative effect of avatar transition delay and providing the design choice of the transition style, we propose a Predict-and-Drive controller to diminish the delay and present the smooth transition of the telepresence avatar. We also introduce a grouping component as an upgrade to immediately calculate a coarse virtual target once the user initiates a transition, which could further eliminate the avatar transition delay. Once having the coarse virtual target or an exactly predicted target, we find the corresponding target for the avatar according to the pre-constructed mapping of objects of interest between two spaces. The avatar control component maintains an artificial potential field of the space and drives the avatar towards the target while respecting the obstacles in the physical environment. We further conduct ablation studies to evaluate the effectiveness of our proposed components. |
Wanchao Su*, Hui Ye*, Shu-Yu Chen, Lin Gao, and Hongbo Fu. DrawingInStyles: Portrait Image Generation and Editing with Spatially Conditioned StyleGAN. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 29(10): 4074 - 4088. October 2023. |
|
 |
Abstract: The research topic of sketch-to-portrait generation has witnessed a boost of progress with deep learning techniques. The recently proposed StyleGAN architectures achieve state-of-the-art generation ability but the original StyleGAN is not friendly for sketch-based creation due to its unconditional generation nature. To address this issue, we propose a direct conditioning strategy to better preserve the spatial information under the StyleGAN framework. Specifically, we introduce Spatially Conditioned StyleGAN (SC-StyleGAN for short), which explicitly injects spatial constraints to the original StyleGAN generation process. We explore two input modalities, sketches and semantic maps, which together allow users to express desired generation results more precisely and easily. Based on SC-StyleGAN, we present DrawingInStyles, a novel drawing interface for non-professional users to easily produce high-quality, photo-realistic face images with precise control, either from scratch or editing existing ones. Qualitative and quantitative evaluations show the superior generation ability of our method to existing and alternative solutions. The usability and expressiveness of our system are confirmed by a user study. |
Lei Li, Hongbo Fu, and Maks Ovjanikov. WSDesc: Weakly Supervised 3D Local Descriptor Learning for Point Cloud Registration. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 29(7): 3368 - 3379. July 2023. |
|
 |
Abstract: In this work, we present a novel method called WSDesc to learn 3D local descriptors in a weakly supervised manner for robust point cloud registration. Our work builds upon recent 3D CNN-based descriptor extractors, which leverage a voxel-based representation to parameterize local geometry of 3D points. Instead of using a predefined fixed-size local support in voxelization, we propose to learn the optimal support in a data-driven manner. To this end, we design a novel differentiable voxelization layer that can back-propagate the gradient to the support size optimization. To train the extracted descriptors, we propose a novel registration loss based on the deviation from rigidity of 3D transformations, and the loss is weakly supervised by the prior knowledge that the input point clouds have partial overlap, without requiring ground-truth alignment information. Through extensive experiments, we show that our learned descriptors yield superior performance on existing geometric registration benchmarks. [Paper] |
Beijia Chen, Hongbo Fu, Kun Zhou, and Youyi Zheng. OrthoAligner: Image-based Teeth Alignment Prediction via Latent Style Manipulation. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 29(8): 3617 - 3629. August 2023. |
|
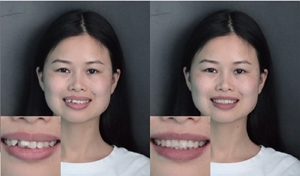 |
Abstract: In this paper, we present OrthoAligner, a novel method to predict the visual outcome of orthodontic treatment in a portrait image. Unlike the state-of-the-art method, which relies on a 3D teeth model obtained from dental scanning, our method generates realistic alignment effects in images without requiring additional 3D information as input and thus making our system readily available to average users. The key of our approach is to employ the 3D geometric information encoded in an unsupervised generative model, i.e., StyleGAN in this paper. Instead of directly conducting translation in the image space, we embed the teeth region extracted from a given portrait to the latent space of the StyleGAN generator and propose a novel latent editing method to discover a geometrically meaningful editing path that yields the alignment process in the image space. To blend the edited mouth region with the original portrait image, we further introduce a BlendingNet to remove boundary artifacts and correct color inconsistency. We also extend our method to short video clips by propagating the alignment effects across neighboring frames. We evaluate our method in various orthodontic cases, compare it to the state-of-the-art and competitive baselines, and validate the effectiveness of each component. [Paper] |
Shi-Sheng Huang, Haoxiang Chen, Jiahui Huang, Hongbo Fu, and Shi-Min Hu. Real-time Globally Consistent 3D Reconstruction with Semantic Priors. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 29(4): 1977 - 1991. April 2023. |
|
 |
Abstract: Maintaining global consistency continues to be critical for online 3D indoor scene reconstruction. However, it is still challenging to generate satisfactory 3D reconstruction in terms of global consistency for previous approaches using purely geometric analysis, even with bundle adjustment or loop closure techniques. In this paper, we propose a novel real-time 3D reconstruction approach which effectively integrates both semantic and geometric cues. The key challenge is how to map this indicative information, i.e. semantic priors, into a metric space as measurable information, thus enabling more accurate semantic fusion leveraging both the geometric and semantic cues. To this end, we introduce a semantic space with a continuous metric function measuring the distance between discrete semantic observations. Within the semantic space, we present an accurate frame-to-model semantic tracker for camera pose estimation, and semantic pose graph equipped with semantic links between submaps for globally consistent 3D scene reconstruction. With extensive evaluation on public synthetic and real-world 3D indoor scene RGB-D datasets, we show that our approach outperforms the previous approaches for 3D scene reconstruction both quantitatively and qualitatively, especially in terms of global consistency.. [Paper, Video] |
Hui Ye*, Kin Chung Kwan*, and Hongbo Fu. 3D curve creation on and around physical objects with mobile AR. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 28(8): 2809 - 2821. Aug. 2022. |
|
 |
Abstract: The recent advance in motion tracking (e.g., Visual Inertial Odometry) allows the use of a mobile phone as a 3D pen, thus significantly benefiting various mobile Augmented Reality (AR) applications based on 3D curve creation. However, when creating 3D curves on and around physical objects with mobile AR, tracking might be less robust or even lost due to camera occlusion or textureless scenes. This motivates us to study how to achieve natural interaction with minimum tracking errors during close interaction between a mobile phone and physical objects. To this end, we contribute an elicitation study on input point and phone grip, and a quantitative study on tracking errors. Based on the results, we present a system for direct 3D drawing with an AR-enabled mobile phone as a 3D pen, and interactive correction of 3D curves with tracking errors in mobile AR. We demonstrate the usefulness and effectiveness of our system for two applications: in-situ 3D drawing, and direct 3D measurement. |
Song-Hai Zhang, Shao-Kui Zhang, Wei-Yu Xie, Cheng-Yang Luo, Yong-Liang Yang, and Hongbo Fu. Fast 3D Indoor Scene Synthesis by Learning Spatial Relation Priors of Objects. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 28(9): 3082 - 3092. September 2022. |
|
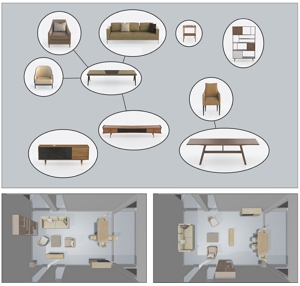 |
Abstract: We present a framework for fast synthesizing indoor scenes, given a room geometry and a list of objects with learnt priors. Unlike existing data-driven solutions, which often learn priors by co-occurrence analysis and statistical model fitting, our method measures the strengths of spatial relations by tests for complete spatial randomness (CSR), and learns discrete priors based on samples with the ability to accurately represent exact layout patterns. With the learnt priors, our method achieves both acceleration and plausibility by partitioning the input objects into disjoint groups, followed by layout optimization using position-based dynamics (PBD) based on the Hausdorff metric. Experiments show that our framework is capable of measuring more reasonable relations among objects and simultaneously generating varied arrangements in seconds compared with the state-of-the-art works. [Paper] |
Dong Du, Xiaoguang Han, Hongbo Fu, Feiyang Wu, Yizhou Yu, Shuguang Cui, and Ligang Liu. SAniHead: Sketching Animal-like 3D Character
Heads Using a View-surface Collaborative Mesh
Generative Network. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 28(6): 2415-2429. June 2022. |
|
 |
Abstract: In the game and film industries, modeling 3D heads plays a very important role in designing characters. Although human head modeling has been researched for a long time, few works have focused on animal-like heads, which are of more diverse shapes and richer geometric details. In this work, we present SAniHead, an interactive system for creating animal-like heads with a mesh representation from dual-view sketches. Our core technical contribution is a view-surface collaborative mesh generative network. Initially, a Graph Convolutional Neural Network(GCNN) is trained to learn the deformation of a template mesh to fit the shape of sketches, giving rise to a coarse model. It is then projected into vertex maps where image-to-image translation networks are performed for detail inference. After back-projecting the inferred details onto the meshed surface, a new GCNN is trained for further detail refinement. The modules of view-based detail inference and surface-based detail refinement are conducted in an alternating cascaded fashion, collaboratively improving the model. A refinement sketching interface is also implemented to support direct mesh manipulation. Experimental results show the superiority of our approach and the usability of our interactive system. Our work also contributes a 3D animal head dataset with corresponding line drawings. |
Yi-Ling Qiao, Yu-Kun Lai, Hongbo Fu, and Lin Gao. Synthesizing Mesh Deformation Sequences with Bidirectional LSTM. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 28(4): 1906-1916. April 2022. |
|
 |
Abstract: Synthesizing realistic 3D mesh deformation sequences is a challenging but important task in computer animation. To achieve this, researchers have long been focusing on shape analysis to develop new interpolation and extrapolation techniques. However, such techniques have limited learning capabilities and therefore often produce unrealistic deformation. Although there are already networks defined on individual meshes, deep architectures that operate directly on mesh sequences with temporal information remain unexplored due to the following major barriers: irregular mesh connectivity, rich temporal information, and varied deformation. To address these issues, we utilize convolutional neural networks defined on triangular meshes along with a shape deformation representation to extract useful features, followed by long short-term memory (LSTM) that iteratively processes the features. To fully respect the bidirectional nature of actions, we propose a new share-weight bidirectional scheme to better synthesize deformations. An extensive evaluation shows that our approach outperforms existing methods in sequence generation, both qualitatively and quantitatively. |
Kin Chung Kwan* and Hongbo Fu. Automatic Image Checkpoint Selection for Guider-Follower Pedestrian Navigation. Computer Graphics Forum (CGF). 40(1): 357-368. Feb. 2021. |
|
 |
Abstract: In recent years guider-follower approaches show a promising solution to the challenging problem of last-mile or indoor pedestrian navigation without micro-maps or indoor floor plans for path planning. However, the success of such guider-follower approaches is highly dependent on a set of manually and carefully chosen image or video checkpoints. This selection process is tedious and error-prone. To address this issue, we first conduct a pilot study to understand how users as guiders select critical checkpoints from a video recorded while walking along a route, leading to a set of criteria for automatic checkpoint selection. By using these criteria, including visibility, stairs, and clearness, we then implement this automation process. The key behind our technique is a lightweight, effective algorithm using left-hand-side and right-hand-side objects for path occlusion detection, which benefits both automatic checkpoint selection and occlusion-aware path annotation on selected image checkpoints. Our experimental results show that our automatic checkpoint selection method works well in different navigation scenarios. The quality of automatically selected checkpoints is comparable to that of manually selected ones and higher than that of checkpoints by alternative automatic methods. |
Qiang Fu, Hai Yan, Hongbo Fu, and Xueming Li. Interactive Design and Preview of Colored Snapshots of Indoor Scenes. Computer Graphics Forum (CGF). 39(7): 543-552. October 2020. |
|
 |
Abstract: This paper presents an interactive system for quickly designing and previewing colored snapshots of indoor scenes. Different from high-quality 3D indoor scene rendering, which often takes several minutes to render a moderately complicated scene under a specific color theme with high-performance computing devices, our system aims at improving the effectiveness of color theme design of indoor scenes and employs an image colorization approach to efficiently obtain high-resolution snapshots with editable colors. Given several pre-rendered, multi-layer, gray images of the same indoor scene snapshot, our system is designed to colorize and merge them into a single colored snapshot. Our system also assists users in assigning colors to certain objects/components and infers more harmonious colors for the unassigned objects based on pre-collected priors to guide the colorization. The quickly generated snapshots of indoor scenes provide previews of interior design schemes with different color themes, making it easy to determine the personalized design of indoor scenes. To demonstrate the usability and effectiveness of this system, we present a series of experimental results on indoor scenes of different types, and compare our method with a state‐of‐the‐art method for indoor scene material and color suggestion and offline/online rendering software packages. |
Deng Yu*, Lei Li*, Youyi Zheng, Manfred Lau, Yi-Zhe Song, Chiew-Lan Tai, and Hongbo Fu. SketchDesc: Learning Local Sketch Descriptors for Multi-view Correspondence. IEEE
Transactions on Circuits and Systems for Video Technology (TCSVT). 31(5): 1738 - 1750. May 2021. |
|
 |
Abstract: In this paper, we study the problem of multi-view sketch correspondence, where we take as input multiple freehand sketches with different views of the same object and predict as output the semantic correspondence among the sketches. This problem is challenging since the visual features of corresponding points at different views can be very different. To this end, we take a deep learning approach and learn a novel local sketch descriptor from data. We contribute a training dataset by generating the pixel-level correspondence for the multi-view line drawings synthesized from 3D shapes. To handle the sparsity and ambiguity of sketches, we design a novel multi-branch neural network that integrates a patch-based representation and a multiscale strategy to learn the pixel-level correspondence among multi-view sketches. We demonstrate the effectiveness of our proposed approach with extensive experiments on hand-drawn sketches and multi-view line drawings rendered from multiple 3D shape datasets. [Paper] |
Guoming Xiong, Qiang Fu (joint first author), Hongbo Fu, Bin Zhou, Guoliang Luo, and Zhigang Deng. Motion Planning for Convertible Indoor Scene Layout Design. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 27(12): 4413-4424. December 2021. |
|
 |
Abstract: We present a system for designing indoor scenes with convertible furniture layouts. Such layouts are useful for scenarios where an indoor scene has multiple purposes and requires layout conversion, such as merging multiple small furniture objects into a larger one or changing the locus of the furniture. We aim at planning the motion for the convertible layouts of a scene with the most efficient conversion process. To achieve this, our system first establishes object-level correspondences between the layout of a given source and that of a reference to compute a target layout, where the objects are re-arranged in the source layout with respect to the reference layout. After that, our system initializes the movement paths of objects between the source and target layouts based on various mechanical constraints. A joint space-time optimization is then performed to program a control stream of object translations, rotations, and stops, under which the movements of all objects are efficient and the potential object collisions are avoided. We demonstrate the effectiveness of our system through various design examples of multi-purpose, indoor scenes with convertible layouts. |
Zhiyong Chen, Rongrui HU, Shihui Guo, Xiangyang Liu, Hongbo Fu, Xiaogang Jin, and Minghong Liao. 3D Upper Body Reconstruction with Sparse Soft Sensors. Soft Robotics (SoRo). 8(2): 226 - 239. April 2021. |
|
 |
Abstract: 3D reconstruction of human body has wide applications for example for customized design of clothes and digital avatar production. Existing vision-based systems for 3D body reconstruction require users to wear minimal or extreme-tight clothes in front of cameras, and thus suffer from privacy problems. In this work we explore a novel solution based on a sparse number of soft sensors on a standard garment, and use it for capturing 3D upper body shape. We utilize the maximal stretching range by modeling the nonlinear performance profile for individual sensors. The body shape can be dynamically reconstructed by analyzing the relationship between mesh deformation and sensor reading, with a learning-based approach. The wearability and exibility of our prototype allow its use in indoor/outdoor environments and for long-term breath monitoring. Our prototype has been extensively evaluated by multiple users with different body sizes and the same user for multiple days. The results show that our garment prototype is comfortable to wear, and achieves the state-of-the-art reconstruction performance with the advantages in privacy projection and application scenarios.. [Paper] |
Lei Li*, Changqing Zou, Youyi Zheng, Qingkun Su, Hongbo Fu, and Chiew-Lan Tai. Sketch-R2CNN: An RNN-Rasterization-CNN Architecture for Vector Sketch Recognition. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 27(9): 3745-3754. Sep. 2021. |
|
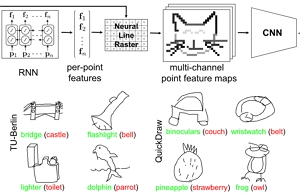 |
Abstract: Sketches in existing large-scale datasets like the recent QuickDraw collection are often stored in a vector format, with strokes consisting of sequentially sampled points. However, most existing sketch recognition methods rasterize vector sketches as binary images and then adopt image classification techniques. In this paper, we propose a novel end-to-end single-branch network architecture RNN-Rasterization-CNN (Sketch-R2CNN for short) to fully leverage the vector format of sketches for recognition. Sketch-R2CNN takes a vector sketch as input and uses an RNN for extracting per-point features in the vector space. We then develop a neural line rasterization module to convert the vector sketch and the per-point features to multi-channel point feature maps, which are subsequently fed to a CNN for extracting convolutional features in the pixel space. Our neural line rasterization module is designed in a differentiable way for end-to-end learning. We perform experiments on existing large-scale sketch recognition datasets and show that the RNN-Rasterization design brings consistent improvement over CNN baselines and that Sketch-R2CNN substantially outperforms the state-of-the-art methods. |
Yuefan Shen, Changgeng Zhang, Hongbo Fu, Kun Zhou, and Youyi Zheng. DeepSketchHair: Deep Sketch-based 3D Hair Modeling. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 27(7): 3250-3263. July 2021. |
|
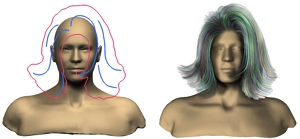 |
Abstract: We present DeepSketchHair, a deep learning based tool for modeling of 3D hair from 2D sketches. Given a 3D bust model as reference, our sketching system takes as input a user-drawn sketch (consisting of hair contour and a few strokes indicating the hair growing direction within a hair region), and automatically generates a 3D hair model, which matches the input sketch both globally and locally. The key enablers of our system are two carefully designed neural networks, namely, S2ONet, which converts an input sketch to a dense 2D hair orientation field; and O2VNet, which maps the 2D orientation field to a 3D vector field. Our system also supports hair editing with additional sketches in new views. This is enabled by another deep neural network, V2VNet, which updates the 3D vector field with respect to the new sketches. All the three networks are trained with synthetic data generated from a 3D hairstyle database. We demonstrate the effectiveness and expressiveness of our tool using a variety of hairstyles and also compare our method with prior art. |
Pengfei Xu, Guohang Yan, Hongbo Fu, Takeo Igarasphi, Chiew-Lan Tai, and Hui Huang. Global Beautification of 2D and 3D Layouts with Interactive Ambiguity Resolution. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 27(4): 2355-2368. April 2021. |
|
 |
Abstract: Specifying precise relationships among graphic elements is often a time-consuming process with traditional alignment tools. Automatic beautification of roughly designed layouts can provide a more efficient solution but often lead to undesired results due to ambiguity problems. To facilitate ambiguity resolution in layout beautification, we present a novel user interface for visualizing and editing inferred relationships through an automatic global layout beautification process. First, our interface provides a preview of the beautified layout with inferred constraints without directly modifying an input layout. In this way, the user can easily keep refining beautification results by interactively repositioning and/or resizing elements in the input layout. Second, we present a gestural interface for editing automatically inferred constraints by directly interacting with the visualized constraints via simple gestures. Our technique is applicable to both 2D and 3D global layout beautification, supported by efficient system implementation that provides instant user feedback. Our user study validates that our tool is capable of creating, editing and refining layouts of graphic elements, and is significantly faster than the standard snap-dragging or command-based alignment tools for both 2D and 3D layout tasks. |
Pengfei Xu, Hongbo Fu, Youyi Zheng, Karan Singh, Hui Huang, and Chiew-Lan Tai. Model-guided 3D sketching. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 25(10): 2927 - 2939. October 2019. |
|
 |
Abstract: We present a novel 3D model-guided interface for in-situ sketching on 3D planes. Our work is motivated by evolutionary design, where existing 3D objects form the basis for conceptual re-design or further design exploration. We contribute a novel workflow that exploits the geometry of an underlying 3D model to infer 3D planes on which 2D strokes drawn that are on and around the 3D model should be meaningfully projected. This provides users with the nearly modeless fluidity of a sketching interface, and is particularly useful for 3D sketching over planes that are not easily accessible or do not preexist. We also provide an additional set of tools, including sketching with explicit plane selection and model-aware canvas manipulation. Our system is evaluated with a user study, showing that our technique is easy to learn and effective for rapid sketching of product design variations around existing 3D models. |
Bin Bao* and Hongbo Fu. Scribble-based Colorization for Creating Smooth-shaded Vector Graphics. Computers & Graphics (CAG) (Special Section on CAD & Graphics 2019). 81: 73 - 81. June 2019. |
|
 |
Abstract: This paper proposes a novel colorizaiton tool for intuitively creating smooth-shaded vector graphics. Our technique takes advantage of diffusion curves, a powerful vector graphics representation. Rather than specifying colors along curves as done in previous works, we allow a user to intuitively paint in regions of arbitrary line drawings. Once the user scribbles on drawings, our algorithm automatically estimates the colors along the curves of drawings, resulting in smooth color regions as close as possible to the user specification. Different from the previous color estimation techniques for image vectorization, A new diffusion curve colorization algorithm is proposed for fitting sparse colors of input scribbles. Our approach is fast and provides instant feedback to the user. We have tested our system on a variety of line drawings with varying shape complexity, and shown that our technique can produce visually pleasing smooth-shaded images intuitively and effectively. |
Lei Li*, Hongbo Fu, and Chiew-Lan Tai. Fast Sketch Segmentation and Labeling with Deep Learning. IEEE Computer Graphics and Applications (CGA) (Special issue on Visual Computing with Deep Learning). 39(2): 38 - 51. March/April 2019. |
|
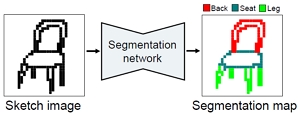 |
Abstract: We present a simple and efficient method based on deep learning to automatically decompose sketched objects into semantically valid parts. We train a deep neural network to transfer existing segmentations and labelings from 3D models to freehand sketches without requiring numerous well-annotated sketches as training data. The network takes the binary image of a sketched object as input and produces a corresponding segmentation map with per-pixel labelings as output. A subsequent post-process procedure with multi-label graph cuts further refines the segmentation and labeling result. We validate our proposed method on two sketch datasets. Experiments show that our method outperforms the state-of-the-art method in terms of segmentation and labeling accuracy and is significantly faster, enabling further integration in interactive drawing systems. We demonstrate the efficiency of our method in a sketch-based modeling application that automatically transforms input sketches into 3D models by part assembly. |
Wanchao Su*, Dong Du*, Xin Yang*, Shizhe Zhou*, and Hongbo Fu. Interactive sketch-based normal map generation with deep neural networks. Proceedings of the ACM on Computer Graphics and Interactive Techniques (PACMGIT) (Special issue on i3D 2018). 1(1): Article No. 22. May 2018. |
|
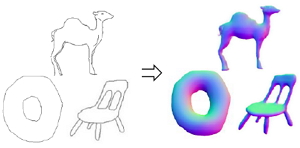 |
Abstract: High-quality normal maps are important intermediates for representing complex shapes. In this paper, we propose an interactive system for generating normal maps with the help of deep learning techniques. Utilizing the Generative Adversarial Network (GAN) framework, our method produces high quality normal maps with sketch inputs. In addition, we further enhance the interactivity of our system by incorporating user-specified normals at selected points. Our method generates high quality normal maps in real time. Through comprehensive experiments, we show the effectiveness and robustness of our method. A thorough user study indicates the normal maps generated by our method achieve a lower perceptual difference from the ground truth compared to the alternative methods. |
Mingze Yuan, Lin Gao, Hongbo Fu, and Shihong Xia. Temporal upsampling of depth maps using a hybrid camera. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 25(3): 1591 - 1602. March 2019. |
|
 |
Abstract: In recent years, consumer-level depth cameras have been adopted for various applications. However, they often produce depth maps at only a moderately high frame rate (approximately 30 frames per second), preventing them from being used for applications such as digitizing human performance involving fast motion. On the other hand, low-cost, high-frame-rate video cameras are available. This motivates us to develop a hybrid camera that consists of a high-frame-rate video camera and a low-frame-rate depth camera and to allow temporal interpolation of depth maps with the help of auxiliary color images. To achieve this, we develop a novel algorithm that reconstructs intermediate depth maps and estimates scene flow simultaneously. We test our algorithm on various examples involving fast, non-rigid motions of single or multiple objects. Our experiments show that our scene flow estimation method is more precise than a tracking-based method and the state-of-the-art techniques. |
Qiang Fu*, Xiaowu Chen, Xiaoyu Su, and Hongbo Fu. Pose-inspired shape synthesis and functional hybrid. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 23(12): 2574-2585. December 2017. |
|
 |
Abstract: We introduce a shape synthesis approach especially for functional hybrid creation that can be potentially used by a human operator under a certain pose. Shape synthesis by reusing parts in existing models has been an active research topic in recent years. However, how to combine models across different categories to design multi-function objects remains challenging, since there is no natural correspondence between models across different categories. We tackle this problem by introducing a human pose to describe object affordance which establishes a bridge between cross-class objects for composite design. Specifically, our approach first identifies groups of candidate shapes which provide affordances desired by an input human pose, and then recombines them as well-connected composite models. Users may control the design process by manipulating the input pose, or optionally specifying one or more desired categories. We also extend our approach to be used by a single operator with multiple poses or by multiple human operators. We show that our approach enables easy creation of nontrivial, interesting synthesized models. |
Quoc Huy Phan*, Hongbo Fu, and Antoni Chan. Color Orchestra: Ordering color palettes for interpolation and prediction. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 24(6): 1942 - 1955. June 2018. |
|
 |
Abstract: Color theme or color palette can deeply influence the quality and the feeling of a photograph or a graphical design. Although color palettes may come from different sources such as online crowd-sourcing, photographs and graphical designs, in this paper, we consider color palettes extracted from fine art collections, which we believe to be an abundant source of stylistic and unique color themes. We aim to capture color styles embedded in these collections by means of statistical models and to build practical applications upon these models. As artists often use their personal color themes in their paintings, making these palettes appear frequently in the dataset, we employed density estimation to capture the characteristics of palette data. Via density estimation, we carried out various predictions and interpolations on palettes, which led to promising applications such as photo-style exploration, real-time color suggestion, and enriched photo recolorization. It was, however, challenging to apply density estimation to palette data as palettes often come as unordered sets of colors, which make it difficult to use conventional metrics on them. To this end, we developed a divide-and-conquer sorting algorithm to rearrange the colors in the palettes in a coherent order, which allows meaningful interpolation between color palettes. To confirm the performance of our model, we also conducted quantitative experiments on datasets of digitized paintings collected from the Internet and received favorable results. |
Bin Sheng, Bowen Liu, Ping Li, Hongbo Fu, Lizhuang Ma, and Enhua Wu. Accelerated robust Boolean operations based on hybrid representations. Computer Aided Geometric Design (Special Issue on Geometric Modeling and Processing 2018). Volume 62: 133 - 153. May 2018. |
|
 |
Abstract: Constructive Solid Geometry (CSG) is one of the popular techniques that is widely applied in 3D modeling. It combines primitive solids using Boolean operations. However, the trade-off between efficiency and robustness of Boolean evaluation is difficult to balance. Previous methods sacrifice either efficiency or robustness to achieve advantages in one perspective. Recent works attempt to achieve excellent performance in both aspects through replacing the conventional vertex-based representations (V-reps) with plane-based representations (P-reps) of polyhedrons. Different from V-reps, the P-reps use plane coefficients as meta-data and can lead to benign robustness. However, methods using P-reps have disadvantages in efficiency compared to methods using V-reps. In this paper, we proposed a Boolean evaluation approach that absorbs both the efficiency of V-reps based methods and robustness of P-reps based methods. We design a Boolean evaluation method combining P-reps with V-reps. The P-reps information is utilized for exact predicate computation while information in V-reps is collected for fast topology query and coarse tests. Our proposed approach is variadic: it evaluates a Boolean expression regarding multi-input meshes as a whole rather than a tree of decomposed binary operations. We conduct massive experiments and compare our results with those generated by the state-of-the-art methods. Experimental results show that our approach is robust for solid inputs and has advantages in performance compared to some previous non-robust methods. [Paper] |
Bin Sheng, Ping Li, Hongbo Fu, Lizhuang Ma, and Enhua Wu. Efficient non-incremental constructive solid geometry evaluation for triangular meshes. Graphical Models (Special issue on Computational Visual Media 2018). Volume 97: 1 - 16. May 2018. |
|
 |
Abstract: 3D surface offsetting is a fundamental geometric operation in CAD/CAE/CAM. In this paper, we propose a super-linear convergent algorithm to generate a well-triangulated and feature-aligned offset surface based on particle system. The key idea is to distribute a set of moveable sites as uniformly as possible while keeping these sites at a specified distance away from the base surface throughout the optimization process. In order to make the final triangulation align with geometric feature lines, we use the moveable sites to predict the potential feature regions, which in turn guide the distribution of moveable sites. Our algorithm supports multiple kinds of input surfaces, e.g., triangle meshes, implicit functions, parametric surfaces and even point clouds. Compared with existing algorithms on surface offsetting, our algorithm has significant advantages in terms of meshing quality, computational performance, topological correctness and feature alignment. [Paper] |
Wenlong Meng*, Shuangmin Chen, Zhenyu Shu, Shi-Qing Xin, Hongbo Fu, and Changhe Tu. Efficiently computing feature-aligned and high-quality polygonal offset surfaces. Computers & Graphics (Special Issue on CAD/Graphics 2017). Volume 70: 62 - 70. Feb. 2018. |
|
 |
Abstract: 3D surface offsetting is a fundamental geometric operation in CAD/CAE/CAM. In this paper, we propose a super-linear convergent algorithm to generate a well-triangulated and feature-aligned offset surface based on particle system. The key idea is to distribute a set of moveable sites as uniformly as possible while keeping these sites at a specified distance away from the base surface throughout the optimization process. In order to make the final triangulation align with geometric feature lines, we use the moveable sites to predict the potential feature regions, which in turn guide the distribution of moveable sites. Our algorithm supports multiple kinds of input surfaces, e.g., triangle meshes, implicit functions, parametric surfaces and even point clouds. Compared with existing algorithms on surface offsetting, our algorithm has significant advantages in terms of meshing quality, computational performance, topological correctness and feature alignment. [Paper] |
Sheng Yang, Kang Chen, Minghua Liu, Hongbo Fu, and Shi-Min Hu. Saliency-aware real-time volumetric fusion for object reconstruction. Computer Graphics Forum (Proceedings of Pacific Graphics 2017). 36(7): 167-174. October 2017. |
|
 |
Abstract: We present a real-time approach for acquiring 3D objects with high fidelity using hand-held consumer-level RGB-D scanning devices. Existing real-time reconstruction methods typically do not take the point of interest into account, and thus might fail to produce clean reconstruction results of desired objects due to distracting objects or backgrounds. In addition, any changes in background during scanning, which can often occur in real scenarios, can easily break up the whole reconstruction process. To address these issues, we incorporate visual saliency into a traditional real-time volumetric fusion pipeline. Salient regions detected from RGB-D frames suggest user-intended objects, and by understanding user intentions our approach can put more emphasis on important targets, and meanwhile, eliminate disturbance of non-important objects. Experimental results on real-world scans demonstrate that our system is capable of effectively acquiring geometric information of salient objects in cluttered real-world scenes, even if the backgrounds are changing. |
Sheng Yang, Jie Xu, Kang Chen, and Hongbo Fu. View suggestion for interactive segmentation of indoor scenes. Computational Visual Media. 3: 131. 2017. |
|
 |
Abstract: Point cloud segmentation is a fundamental problem. Due to the complexity of real-world scenes and the limitations of 3D scanners, interactive segmentation is currently the only way to cope with all kinds of point clouds. However, interactively segmenting complex and large-scale scenes is very time-consuming. In this paper, we present a novel interactive system for segmenting point cloud scenes. Our system automatically suggests a series of camera views, in which users can conveniently specify segmentation guidance. In this way, users may focus on specifying segmentation hints instead of manually searching for desirable views of unsegmented objects, thus significantly reducing user effort. To achieve this, we introduce a novel view preference model, which is based on a set of dedicated view attributes, with weights learned from a user study. We also introduce support relations for both graph-cut-based segmentation and finding similar objects. Our experiments show that our segmentation technique helps users quickly segment various types of scenes, outperforming alternative methods. |
Shi-Sheng Huang, Hongbo Fu, Lin-Yu Wei, and Shi-Min Hu. Support Substructures: Support-induced part-level structural representation. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 22(8): 2024-36. Aug 2016. |
|
 |
Abstract: In this work we explore a support-induced structural organization of object parts. We introduce the concept of support substructures, which are special subsets of object parts with support and stability. A bottom-up approach is proposed to identify such substructures in a support relation graph. We apply the derived high-level substructures to part-based shape reshuffling between models, resulting in nontrivial functionally plausible model variations that are difficult to achieve with symmetry-induced substructures by the state of the art. We also show how to automatically or interactively turn a single input model to new functionally plausible shapes by structure rearrangement and synthesis, enabled by support substructures. To the best of our knowledge no single existing method has been designed for all these applications. |
Qiang Fu*, Xiaowu Chen, Xiaoyu Su, Jia Li, and Hongbo Fu. Structure-adaptive Shape Editing for Man-made Objects. Computer Graphics Forum (Proceedings of Eurographics 2016). 35(2): 27-36. May 9-13, 2016. |
|
 |
Abstract: One of the challenging problems for shape editing is to adapt shapes with diversified structures for various editing needs. In this paper we introduce a shape editing approach that automatically adapts the structure of a shape being edited with respect to user inputs. Given a category of shapes, our approach first classifies them into groups based on the constituent parts. The group-sensitive priors, including both inter-group and intra-group priors, are then learned through statistical structure analysis and multivariate regression. By using these priors, the inherent characteristics and typical variations of shape structures can be well captured. Based on such group-sensitive priors, we propose a framework for real-time shape editing, which adapts the structure of shape to continuous user editing operations. Experimental results show that the proposed approach is capable of both structure-preserving and structure-varying shape editing. |
Wing Ho Andy Li*, Kening Zhu, and Hongbo Fu. Exploring the design space of bezel-initiated gestures for mobile interaction. International Journal of Mobile Human Computer Interaction. Volume 9 Issue 1, Jan. 2017. |
|
 |
Abstract: Bezel enables useful gestures supplementary to primary surface gestures for mobile interaction. However, the existing works mainly focus on researcher-designed gestures, which utilized only a subset of the design space. In order to explore the design space, we present a modified elicitation study, during which the participants designed bezel-initiated gestures for four sets of tasks. Different from traditional elicitation studies, ours encourages participants to design new gestures. We do not focus on individual tasks or gestures, but perform a detailed analysis of the collected gestures as a whole, and provide findings which could benefit designers of bezel-initiated gestures. |
Shi-Sheng Huang, Hongbo Fu, and Shi-Ming Hu. Structure guided interior scene synthesis via graph matching. Graphical Models. Volume 85, Pages 46-55, May 2016. |
|
 |
Abstract: We present a method for reshuffle-based 3D interior scene synthesis guided by scene structures. Given several 3D scenes, we form each 3D scene as a structure graph associated with a relationship set. Considering both the object similarity and relation similarity, we then establish a furniture-object-based matching between scene pairs via graph matching. Such a matching allows us to merge the structure graphs into a unified structure, i.e., Augmented Graph (AG). Guided by the AG , we perform scene synthesis by reshuffling objects through three simple operations, i.e., replacing, growing and transfer. A synthesis compatibility measure considering the environment of the furniture objects is also introduced to filter out poor-quality results. We show that our method is able to generate high-quality scene variations and out- performs the state of the art. |
Qiang Fu*, Xiaowu Chen, Xiaoyu Su, and Hongbo Fu. Natural lines inspired 3D shape re-design. Graphical Models. Volume 85, Pages 1-10, May 2016. |
|
 |
Abstract: We introduce an approach for re-designing 3D shapes inspired by natural lines such as the contours and skeletons extracted from the natural objects in images. Designing an artistically creative and visually pleasing model is not easy for novice users. In this paper, we propose to convert such a design task to a computational procedure. Given a 3D object, we first compare its editable lines with various lines extracted from the image database to explore the candidate reference lines. Then a parametric deformation method is employed to reshape the 3D object guided by the reference lines. We show that our approach enables users to quickly create non-trivial and interesting re-designed 3D objects. We also conduct a user study to validate the usability and effectiveness of our approach. |
Wing Ho Andy Li*, Hongbo Fu, and Kening Zhu. BezelCursor: Bezel-initiated cursor for one-handed target acquisition on mobile touch screens. International Journal of Mobile Human Computer Interaction. Volume 8, Issue 1, Jan-March 2016. |
|
 |
Abstract: We present BezelCursor, a novel one-handed thumb interaction technique for target acquisition on mobile touch screens of various sizes. Our technique combines bezel-initiated interaction and pointing gesture to solve the problem of limited screen accessibility afforded by the thumb. With a fixed, comfortable grip of a mobile touch device, a user may employ our tool to easily and quickly access a target located anywhere on the screen, using a single fluid action. Unlike the existing technologies, our technique requires no explicit mode switching to invoke and can be smoothly used together with commonly adopted interaction styles such as direct touch and dragging. Our user study shows that BezelCursor requires less grip adjustment, and is more accurate or faster than the state-of-the-art techniques when using a fixed secure grip. |
Quoc Huy Phan*, Hongbo Fu, and Antoni Chan. FlexyFont: Learning transferring rules for flexible typeface synthesis. Computer Graphics Forum (Proceedings of Pacific Graphics 2015). 34(7): 245-256. Oct. 2015. |
|
 |
Abstract: Maintaining consistent styles across glyphs is an arduous task in typeface design. In this work we introduce FlexyFont, a flexible tool for synthesizing a complete typeface that has a consistent style with a given small set of glyphs. Motivated by a key fact that typeface designers often maintain a library of glyph parts to achieve a consistent typeface, we intend to learn part consistency between glyphs of different characters across typefaces. We take a part assembling approach by firstly decomposing the given glyphs into semantic parts and then assembling them according to learned sets of transferring rules to reconstruct the missing glyphs. To maintain style consistency, we represent the style of a font as a vector of pairwise part similarities. By learning a distribution over these feature vectors, we are able to predict the style of a novel typeface given only a few examples. We utilize a popular machine learning method as well as retrieval-based methods to quantitatively assess the performance of our feature vector, resulting in favorable results. We also present an intuitive interface that allows users to interactively create novel typefaces with ease. The synthesized fonts can be directly used in real-world design. |
Xiaoyu Su, Xiaowu Chen, Qiang Fu, and Hongbo Fu. Cross-class 3D object synthesis guided by reference examples. Computers & Graphics (Special Issue on CAD/Graphics 2015). 54: 145-153. Feb. 2016. Best Paper Award |
|
 |
Abstract: Re-combining parts of existing 3D object models is an interesting and efficient technique to create novel shape collections. However, due to the lack of direct parts’ correspondence across different shape families, such data-driven modeling approaches in literature are limited to the synthesis of in-class shapes only. To address the problem, this paper proposes a novel approach to create 3D shapes via re-combination of cross-category object parts from an existing database of different model families. In our approach, a reference shape containing multi-functional constituent parts is pre-specified by users, and its design style is then reused to guide the creation process. To this end, the functional substructures are first extracted for the reference shape. After that, we explore a series of category pairs which are potential replacements for the functional substructures of the reference shape to make interesting variations. We demonstrate our ideas using various examples, and present a user study to evaluate the usability and efficiency of our technique. [Paper] |
Changqing Zou*, Shifeng Chen, Hongbo Fu, and Jianzhuang Liu. Progressive 3D reconstruction of planar-faced manifold objects with DRF-based line drawing decomposition. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 21(2): 252-263. Feb. 2015. |
|
 |
Abstract: This paper presents an approach for reconstructing polyhedral objects from single-view line drawings. Our approach separates a complex line drawing representing a manifold object into a series of simpler line drawings, based on the degree of reconstruction freedom (DRF). We then progressively reconstruct a complete 3D model from these simpler line drawings. Our experiments show that our decomposition algorithm is able to handle complex drawings which are challenging for the state of the art. The advantages of the presented progressive 3D reconstruction method over the existing reconstruction methods in terms of both robustness and efficiency are also demonstrated. [Paper] |
Changqing Zou*, Xiaojiang Peng, Hao Lv, Shifeng Chen, Hongbo Fu, and Jianzhuang Liu. Sketch-based 3-D modeling for piecewise planar objects in single images. Computers & Graphics (Special Issue of SMI 2014). 46(2015): 130-137. Feb. 2015. |
|
 |
Abstract: 3-D object modeling from single images has many applications in computer graphics and multimedia. Most previous 3-D modeling methods which directly recover 3-D geometry from single images require user interactions during the whole modeling process. In this paper, we propose a semi-automatic 3-D modeling approach to recover accurate 3-D geometry from a singe image of a piecewise planar object with less user interaction. Our approach concentrates on these three aspects: 1) requiring rough sketch input only, 2) accurate modeling for a large class of objects, and 3) automatically recovering the hidden part of an object and providing a complete 3-D model. Experimental results on various objects show that the proposed approach provides a good solution to these three problems. [Paper] |
Zhe Huang, Jiang Wang, Hongbo Fu, and Rynson Lau. Structured mechanical collage. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 20(7):
1076-1082, July 2014. |
|
 |
Abstract: We present a method to build 3D structured mechanical collages consisting of numerous elements from the database given artist-designed proxy models. The construction is guided by some graphic design principles, namely unity, variety and contrast. Our results are visually more pleasing than previous works as confirmed by a user study. [Paper]; [Video]; [Suppl]; [More results] |
Xiaoguang Han*, Hongbo Fu, Hanlin Zheng*, Ligang Liu, and Jue Wang. A video-based interface for hand-driven stop motion animation production. IEEE Computer Graphics and Applications (CGA). 33(6): 70-81. 2013.
|
|
 |
Abstract: Stop motion is a well-established animation technique, but its production is often laborious and requires craft skills. We present a new video-based interface which is capable of animating the vast majority of everyday objects in stop motion style in a more flexible and intuitive way. It allows animators to perform and capture motions continuously instead of breaking them into small increments and shooting one still picture per increment. More importantly, it permits direct hand manipulation without resorting to rigs, achieving more natural object control for beginners. The key component of our system is a two-phase keyframe-based capturing and processing workflow, assisted by computer vision techniques. We demonstrate that our system is efficient even for amateur animators to generate high quality stop motion animations of a wide variety of objects. |
Bin Liao, Chunxia Xiao, Liqiang Jin, and Hongbo Fu. Efficient feature-preserving local projection operator for geometry reconstruction. Computer Aided Design (CAD). 45(5): 861-874. |
|
 |
Abstract: This paper proposes an efficient and Feature-preserving Locally Optimal Projection operator (FLOP) for geometry reconstruction. Our operator is bilateral weighted, taking both spatial and geometric feature information into consideration for feature-preserving approximation. We then present an accelerated FLOP operator based on the random sampling of the Kernel Density Estimate (KDE), which produces reconstruction results close to those generated using the complete point set data, to within a given accuracy. Additionally, we extend our approach to time-varying data reconstruction, called Spatial-Temporal Locally Optimal Projection operator (STLOP), which efficiently generates temporally coherent and stable features-preserving results. The experimental results show that the proposed algorithms are efficient and robust for feature-preserving geometry reconstruction on both static models and time-varying data sets. [Paper] |
Jingbo Liu, Oscar
Kin-Chung Au, Hongbo Fu, and Chiew-Lan
Tai. Two-finger gestures for 6DOF manipulation of 3D objects. Computer Graphics Forum (CGF): special issue of Pacific Graphics 2012. 31(7): 2047-2055. (Acceptance rate: 19.6%) |
|
 |
Abstract: Multitouch input devices afford effective solutions for 6DOF (six Degrees of Freedom) manipulation of 3D objects. Mainly focusing on large-size multitouch screens, existing solutions typically require at least three fingers and bimanual interaction for full 6DOF manipulation. However, single-hand, two-finger operations are preferred especially for portable multitouch devices (e.g., popular smartphones) to cause less hand occlusion and relieve the other hand for necessary tasks like holding the devices. Our key idea for full 6DOF control using only two contact fingers is to introduce two manipulation modes and two corresponding gestures by examining the moving characteristics of the two fingers, instead of the number of fingers or the directness of individual fingers as done in previous works. We solve the resulting binary classification problem using a learning-based approach. Our pilot experiment shows that with only two contact fingers and typically unimanual interaction, our technique is comparable to or even better than the state-of-the-art techniques. |
Oscar
Kin-Chung Au, Chiew-Lan
Tai, and Hongbo Fu. Multitouch gestures for constrained transformation of 3D objects. Computer Graphics Forum (CGF): special issue of Eurographics 2012. 31(2): 651-660. (Acceptance rate: 25%) |
|
 |
Abstract: 3D transformation widgets allow constrained manipulations of 3D objects and are commonly used in many 3D applications for fine-grained manipulations. Since traditional transformation widgets have been mainly designed for mouse-based systems, they are not user friendly for multitouch screens. There is little research on how to use the extra input bandwidth of multitouch screens to ease constrained transformation of 3D objects. This paper presents a small set of multitouch gestures which offers a seamless control of manipulation constraints (i.e., axis or plane) and modes (i.e., translation, rotation or scaling). Our technique does not require any complex manipulation widgets but candidate axes, which are for visualization rather than direct manipulation. Such design not only minimizes visual clutter but also tolerates imprecise touch-based inputs. To further expand our axis-based interaction vocabulary, we introduce intuitive touch gestures for relative manipulations, including snapping and borrowing axes of another object. A user study shows that our technique is more effective than a direct adaption of standard transformation widgets to the tactile paradigm. [Paper] |
Lei Zhang, Hua Huang, and Hongbo Fu. EXCOL: an EXtract-and-COmplete Layering
approach to cartoon animation reusing. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 18(7): 1156-1169. 2012. |
|
 |
Abstract: We introduce the EXCOL method (EXtract-and-COmplete Layering) — a novel cartoon animation processing technique to convert a traditional animated cartoon video into multiple semantically meaningful layers. Our technique is inspired by vision-based layering techniques but focuses on shape cues in both the extraction and completion steps to reflect the unique characteristics of cartoon animation. For layer extraction, we define a novel similarity measure incorporating both shape and color of automatically segmented regions within individual frames and propagate a small set of user-specified layer labels among similar regions across frames. By clustering regions with the same labels, each frame is appropriately partitioned into different layers, with each layer containing semantically meaningful content. Then a warping-based approach is used to fill missing parts caused by occlusion within the extracted layers to achieve a complete representation. EXCOL provides a flexible way to effectively reuse traditional cartoon animations with only a small amount of user interaction. It is demonstrated that our EXCOL method is effective and robust, and the layered representation benefits a variety of applications in cartoon animation processing. [Paper] |
Youyi Zheng, Hongbo Fu, Oscar
Kin-Chung Au, and Chiew-Lan
Tai. Bilateral normal filtering for mesh denoising. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 17(10): 1521-1530. 2011. |
|
 |
Abstract: Decoupling local geometric features from the spatial location of a mesh is crucial for feature-preserving mesh denoising. This paper focuses on first-order features, i.e., facet normals, and presents a simple yet effective anisotropic mesh denoising framework via normal field denoising. Unlike previous denoising methods based on normal filtering, which process normals defined on the Gauss sphere, our method considers normals as a surface signal defined over the original mesh. This allows the design of a novel bilateral normal filter that depends on both spatial distance and signal distance. Our bilateral filter is a more natural extension of the elegant bilateral filter for image denoising than those used in previous bilateral mesh denoising methods. Besides applying this bilateral normal filter in a local, iterative scheme, as common in most of previous works, we present for the first time a global, non-iterative scheme for anisotropic denoising. We show that the former scheme is faster and more effective for denoising extremely noisy meshes while the latter scheme is more robust to irregular surface sampling. We demonstrate that both our feature-preserving schemes generally produce visually and numerically better denoising results than previous methods, especially at challenging regions with sharp features or irregular sampling. [Paper] |
Youyi Zheng, Hongbo Fu, Daniel Cohen-Or, Oscar
Kin-Chung Au, and Chiew-Lan
Tai. Component-wise controllers for structure-preserving shape manipulation. Computer Graphics Forum (CGF): special issue of Eurographics 2011. 30(2): 563-572. (Acceptance rate: 17.4%) |
|
 |
Abstract: Recent shape editing techniques, especially for man-made models, have gradually shifted focus from maintaining local, low-level geometric features to preserving structural, high-level characteristics like symmetry and parallelism. Such new editing goals typically require a pre-processing shape analysis step to enable subsequent shape editing. Observing that most editing of shapes involves manipulating their constituent components, we introduce component-wise controllers that are adapted to the component characteristics inferred by shape analysis. The controllers capture the natural degrees of freedom of individual components and thus provide an intuitive user interface for editing. A typical model often results in a moderate number of controllers, allowing easy establishment of semantic relations among them by automatic shape analysis supplemented with user interaction. We propose a component-wise propagation algorithm to automatically preserve the established inter-relations while maintaining the defining characteristics of individual controllers and respecting the user-specified modeling constraints. We extend these ideas to a hierarchical setup, allowing the user to adjust the tool complexity with respect to the desired modeling complexity. We demonstrate the effectiveness of our technique on a wide range of engineering models with structural features, often containing multiple connected pieces. |
Oscar
Kin-Chung Au, Chiew-Lan
Tai, Daniel Cohen-Or, Youyi Zheng, and Hongbo Fu. Electors voting for fast automatic shape correspondence. Computer Graphics Forum (CGF): special issue of Eurographics 2010. 29(2): 645-654. (Acceptance rate: 20%) |
|
 |
Abstract: This paper challenges the difficult problem of automatic semantic correspondence between two given shapes which are semantically similar but possibly geometrically very different (e.g., a dog and an elephant). We argue that the challenging part is the establishment of a sparse correspondence and show that it can be efficiently solved by considering the underlying skeletons augmented with intrinsic surface information. To avoid potentially costly direct search for the best combinatorial match between two sets of skeletal feature nodes, we introduce a statistical correspondence algorithm based on a novel voting scheme, which we call electors voting. The electors are a rather large set of correspondences which then vote to synthesize the final correspondence. The electors are selected via a combinatorial search with pruning tests designed to quickly filter out a vast majority of bad correspondence. This voting scheme is both efficient and insensitive to parameter and threshold settings. The effectiveness of the method is validated by precision-recall statistics with respect to manually defined ground truth. We show that high quality correspondences can be instantaneously established for a wide variety of model pairs, which may have different poses, surface details, and only partial semantic correspondence. |
Wei-Lwun Lu, Kevin P. Murphy, James J. Little, Alla Sheffer, and Hongbo Fu. A hybrid Conditional Random Field for estimating the underlying ground surface from airborne LiDAR data. IEEE Transactions on Geoscience and Remote Sensing (TGARS). 47(8): 2913-2922. 2009. |
|
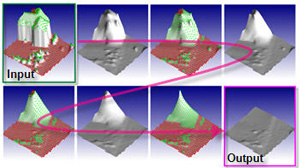 |
Abstract:
Airborne laser scanners (LiDAR) return point clouds of millions of points imaging large regions. It is very challenging to recover the bare earth, i.e., the surface remaining after the buildings and vegetative cover have been identified and removed; manual correction of the recovered surface is very costly. Our solution combines classification into ground and non-ground with reconstruction of the continuous underlying surface. We define a joint model on the class labels and estimated surface, $p(\vc,\vz|\vx)$, where $c_i \in \{0,1\}$ is the label of point $i$ (ground or non-ground), $z_i$ is the estimated bare-earth surface at point $i$, and $x_i$ is the observed height of point $i$. We learn the parameters of this CRF using supervised learning. The graph structure is obtained by triangulating the point clouds. Given the model, we compute a MAP estimate of the surface, $\arg \max p(\vz|\vx)$, using the EM algorithm, treating the labels $\vc$ as missing data. Extensive testing shows that the recovered surfaces agree very well with those reconstructed from manually corrected data. Moreover, the resulting classification of points is competitive with the best in the literature. |
Tiberiu Popa, Qingnan Zhou, Derek Bradley, Vladislav Kraevoy, Hongbo Fu, Alla Sheffer, and Wolfgang Heidrich. Wrinkling captured garments using space-time data-driven deformation. Computer Graphics Forum (CGF): special issue of Eurographics 2009. 28(2): 427--435. (Acceptance rate: 23%) |
|
 |
Abstract: The presence of characteristic fine folds is important for modeling realistic looking virtual garments. While recent
garment capture techniques are quite successful at capturing the low-frequency garment shape and motion over
time, they often fail to capture the numerous high-frequency folds, reducing the realism of the reconstructed spacetime
models. In our work we propose a method for reintroducing fine folds into the captured models using datadriven
dynamic wrinkling. We first estimate the shape and position of folds based on the original video footage
used for capture and then wrinkle the surface based on those estimates using space-time deformation. Both steps
utilize the unique geometric characteristics of garments in general, and garment folds specifically, to facilitate the
modeling of believable folds. We demonstrate the effectiveness of our wrinkling method on a variety of garments
that have been captured using several recent techniques. |
Chunxia
Xiao, Hongbo Fu, and Chiew-Lan
Tai. Hierarchical
aggregation for efficient shape extraction. Springer The Visual Computer (TVC). 25(3): 267-278, Feburary 2009. |
|
 |
Abstract: This paper presents an efficient framework which supports both automatic and interactive shape extraction from surfaces. Unlike most of the existing hierarchical shape extraction methods, which are based on computationally expensive top-down algorithms, our framework employs a fast bottom-up hierarchical method with multiscale aggregation. We introduce a geometric similarity measure, which operates at multiple scales and guarantees that a hierarchy of high-level features are automatically found through local adaptive aggregation. We also show that the aggregation process allows easy incorporation of user-specified constraints, enabling users to interactively extract features of interest. Both our automatic and the interactive shape extraction methods do not require explicit connectivity information, and thus are applicable to unorganized point sets. Additionally, with the hierarchical feature representation, we design a simple and effective method to perform partial shape matching, allowing efficient search of self-similar features across the entire surface. Experiments show that our methods robustly extract visually meaningful features and are significantly faster than related methods. [Paper] |
Xiangye Xiao, Qiong Luo, Dan Hong, Hongbo Fu, Xing Xie, and Wei-Ying Ma. Browsing on small displays by transforming web pages into hierarchically structured sub-pages. ACM Transactions on the Web (TWEB). 2009. Article No 4. |
|
|
Kun Xu, Yuntao
Jia, Hongbo Fu, Shimin
Hu, and Chiew-Lan Tai. Spherical
piecewise constant basis functions for all-frequency precomputed
radiance transfer. IEEE
Transactions on Visualization and Computer Graphics (TVCG). 14(2):
454-467, March/April, 2008. (IEEE TVCG Featured Article) [citation] |
|
 |
Abstract:
This paper presents a novel basis function, called spherical piecewise
constant basis function (SPCBF),
for precomputed radiance transfer. SPCBFs have several desirable
properties: rotatability, ability to represent all-frequency signals,
and support for efficient multiple product. By partitioning the
illumination sphere into a set of subregions, and associating each
subregion with an SPCBF valued 1 inside the region and 0 elsewhere, we
precompute the light coefficients using the resulting SPCBFs. We
run-time approximate BRDF and visibility coefficients with the same set
of SPCBFs through fast lookup of summed-area-table
(SAT) and visibility distance table (VDT),
respectively. SPCBFs enable new effects such as object rotation in
all-frequency rendering of dynamic scenes and on-the-fly BRDF editing
under rotating environment lighting. With graphics hardware
acceleration, our method achieves real-time frame rates. |
Chunxia Xiao, Shu
Liu, Hongbo
Fu, Chengchun Lin, Chengfang Song, Zhiyong Huang, Fazhi He, and Qunsheng
Peng. Video completion and synthesis. Journal of Computer Animation and Virtual World (CAVW): Special Issue of Computer Animation & Social Agents (CASA 2008). 19(3-4): 341-353, 2008. |
|
|
Hongbo
Fu, Oscar Kin-Chung Au, and Chiew-Lan
Tai. Effective derivation
of similarity transformations for implicit Laplacian mesh editing, Computer
Graphics Forum (CGF).
26(1): 34-45, March 2007. (a previous version appeared as a technical report) [citation] |
|
 |
Abstract:
Laplacian coordinates as a local shape descriptor have been employed in
mesh editing. As they are encoded in the global coordinate system, they
need to be transformed locally to reflect the changed local features of
the deformed surface. We present a novel implicit Laplacian editing
framework which is linear and effectively captures local rotation
information during editing. Directly representing rotation with respect
to vertex positions in 3D space leads to a nonlinear system. Instead,
we first compute the affine transformations implicitly defined for all
the Laplacian coordinates by solving a large sparse linear system, and
then extract the rotation and uniform scaling information from each
solved affine transformation. Unlike existing differential-based mesh
editing techniques, our method produces visually pleasing deformation
results under large angle rotations or big-scale translations of
handles. Additionally, to demonstrate the advantage of our editing
framework, we introduce a new intuitive editing technique, called
configuration-independent merging, which produces the same merging
result independent of the relative position, orientation, scale of
input meshes. |


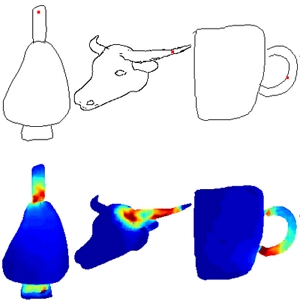

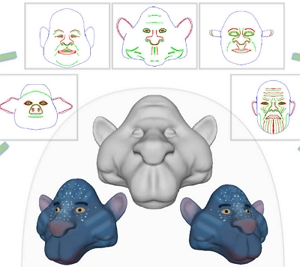

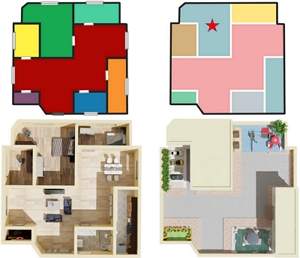



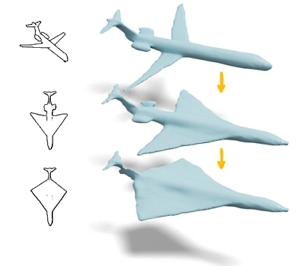
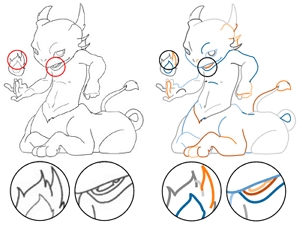



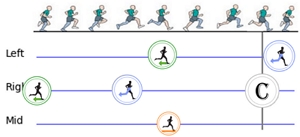
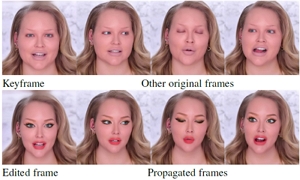
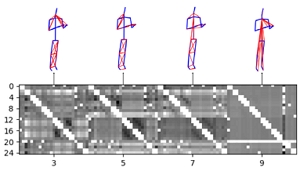
|
Oscar
Kin-Chung Au, Chiew-Lan Tai, and Ligang
Liu, Hongbo Fu. Dual Laplacian
editing for meshes, IEEE
Transactions on Visualization and Computer Graphics (TVCG). 12(3):
386-395, MAY/JUNE 2006. (a previous version appeared as a technical report) [citation]
|
|
 |
Abstract:
Recently, differential information as local intrinsic feature
descriptors has been used for mesh editing. Given certain user input as
constraints, a deformed mesh is reconstructed by minimizing the changes
in the differential information. Since the differential information is
encoded in a global coordinate system, it must somehow be transformed
to fit the orientations of details in the deformed surface, otherwise
distortion will appear. We observe that visually pleasing deformed
meshes should preserve both local parameterization and geometry
details. We propose to encode these two types of information in the
dual mesh domain due to the simplicity of the neighborhood structure of
dual mesh vertices. Both sets of information are nondirectional and
nonlinearly dependent on the vertex positions. Thus, we present a novel
editing framework that iteratively updates both the primal vertex
positions and the dual Laplacian coordinates to progressively reduce
distortion in parametrization and geometry. Unlike previous related
work, our method can produce visually pleasing deformations with simple
user interaction, requiring only the handle positions, not local frames
at the handles. |
Conference and Exhibition
Xuanyu Wang, Weizhan Zhang, and Hongbo Fu. A3RT: Attention-Aware AR Teleconferencing with
Life-Size 2.5D Video Avatars. IEEE VR 2024. 211 - 221. Orlando, FL, USA. March 2024. |
|
 |
Abstract: Augmented Reality (AR) teleconferencing aims to enable remotely separated users to meet with each other in their own physical spaces as if they are face-to-face. Among all solutions, the video-avatarbased approach has the advantage of balancing fidelity and the sense of co-presence using easy-to-setup devices, including only a camera and an AR Head-Mounted Display (HMD). However, non-verbal cues indicating “who is looking at whom” are always lost or misdelivered in multiparty teleconferencing experiences. To make users aware of such non-verbal cues, existing solutions explore screen-based visualizations, incorporate additional hardware, or alter to use a virtual avatar representation. However, they lack immersion, are less feasible for everyday usage due to complex installations, or lose the fidelity of remote users’ authentic appearances. In this paper, we decompose such attention awareness into the awareness of being looked at and the awareness of attention between other users and address them in a decoupled process. Specifically, through a user study, we first find an unobtrusive and reasonable layout “Attention Circle” to retarget a looker’s head gaze to the one being looked at. We then conduct the second user study to find an effective and intuitive “rotatable 2.5D video avatar with attention thumbnail” visualization to aid users in being aware of other users’ attention. With the design choice distilled from the studies, we implement A3RT, a proof-of-concept prototype system that empowers attentionaware 2.5D-video-avatar-based multiparty AR teleconferencing in an easy, everyday setup. Ablation and usability studies on the prototype verify the effectiveness of our proposed components and the full system.. [Paper] |
Jiaxiang Shang, Yu Zeng, Xin Qiao, Xin Wang, Runze Zhang, Guangyuan Sun, Vishal Patel, and Hongbo Fu. JR2Net: Joint Face Reconstruction and Reenactment. AAAI 2023. Washington, DC, USA. February 2023. |
|
 |
Abstract: Face reenactment and reconstruction benefit various applications in self-media, VR, etc. Recent face reenactment methods use 2D facial landmarks to implicitly retarget facial expressions and poses from driving videos to source images, while they suffer from pose and expression preservation issues for cross-identity scenarios, i.e., when the source and the driving subjects are different. Current self-supervised face reconstruction methods also demonstrate impressive results. However, these methods do not handle large expressions well, since their training data lacks samples of large expressions, and 2D facial attributes are inaccurate on such samples. To mitigate the above problems, we propose to explore the inner connection between the two tasks, i.e., using face reconstruction to provide sufficient 3D information for reenactment, and synthesizing videos paired with captured face model parameters through face reenactment to enhance the expression module of face reconstruction. In particular, we propose a novel cascade framework named JR2Net for Joint Face Reconstruction and Reenactment, which begins with the training of a coarse reconstruction network, followed by a 3D-aware face reenactment network based on the coarse reconstruction results. In the end, we train an expression tracking network based on our synthesized videos composed by image-face model parameter pairs. Such an expression tracking network can further enhance the coarse face reconstruction. Extensive experiments show that our JR2Net outperforms the state-of-the-art methods on several face reconstruction and reenactment benchmarks. |
Yilan Chen*, Kin Chung Kwan, Li-Yi Wei, and Hongbo Fu. Autocomplete Repetitive Stroking with Image Guidance. SIGGRAPH Asia 2021 Technical Communications. 36-44. December 2021. The extended version will appear in a special issue of Computational Visual Media. |
|
 |
Abstract: Image-guided drawing can compensate for the lack of skills but often requires a significant number of repetitive strokes to create textures. Existing automatic stroke synthesis methods are usually limited to predefined styles or require indirect manipulation that may break the spontaneous flow of drawing. We present a method to autocomplete repetitive short strokes during users' normal drawing process. Users can draw over a reference image as usual. At the same time, our system silently analyzes the input strokes and the reference to infer strokes that follow users' input style when certain repetition is detected. Users can accept, modify, or ignore the system predictions and continue drawing, thus maintaining the fluid control of drawing. Our key idea is to jointly analyze image regions and operation history for detecting and predicting repetitions. The proposed system can effectively reduce users' workload in drawing repetitive short strokes and facilitates users in creating results with rich patterns. |
Songhai Zhang, Xiangli Li, Yingtian Liu, and Hongbo Fu. Scale-aware Insertion of Virtual Objects in Monocular Videos. ISMAR 2020. 36-44. November 2020. |
|
 |
Abstract: In this paper, we propose a scale-aware method for inserting virtual objects with proper sizes into monocular videos. To tackle the scale ambiguity problem of geometry recovery from monocular videos, we estimate the global scale objects in a video with a Bayesian approach incorporating the size priors of objects, where the scene objects sizes should strictly conform to the same global scale and the possibilities of global scales are maximized according to the size distribution of object categories. To do so, we propose a dataset of sizes of object categories: Metric-Tree, a hierarchical representation of sizes of more than 900 object categories with the corresponding images. To handle the incompleteness of objects recovered from videos, we propose a novel scale estimation method that extracts plausible dimensions of objects for scale optimization. Experiments have shown that our method for scale estimation performs better than the state-of-the-art methods, and has considerable validity and robustness for different video scenes. Metric-Tree has been made available at: https://metric-tree.github.io |
Shi-Sheng Huang, Ze-Yu Ma, Tai-Jiang Mu, Hongbo Fu, and Shi-Min Hu. Lidar-Monocular Visual Odometry using Point and Line Features. ICRA 2020. Paris, France. 31 May - 4 June 2020. |
|
 |
Abstract: We introduce a novel lidar-monocular visual odometry approach using point and line features. Compared to previous point-only based lidar-visual odometry, our approach leverages more environment structure information by introducing both point and line features into pose estimation. We provide a robust method for point and line depth extraction, and formulate the extracted depth as prior factors for pointline bundle adjustment, which greatly reduces the features' 3D ambiguity and thus improves the pose estimation accuracy. Besides, we also provide a purely visual motion tracking and a novel scale correction scheme, leading to an efficient lidarmonocular visual odometry system with high accuracy. The evaluations on the public KITTI odometry benchmark show that our technique achieves more accurate pose estimation than the state-of-the-art approaches, and is sometimes even better than those leveraging semantic information. [Paper] |
Yu-Hui Wen, Lin Gao, Hongbo Fu, Fang-Lue Zhang, and Shihong Xia. Graph CNNs with Motif and Variable Temporal Block for Skeleton-based Action Recognition. AAAI 2019. Haiwaii, USA, January 27 - Feburary 1, 2019. |
|
 |
Abstract: Hierarchical structure and different semantic roles of joints in human skeleton convey important information for action recognition. Conventional graph convolution methods for modeling skeleton structure consider only physically connected neighbors of each joint, and the joints of the same type, thus failing to capture high-order information. In this work, we propose a novel model with motif-based graph convolution to encode hierarchical spatial structure, and a variable temporal dense block to exploit local temporal information over different ranges of human skeleton sequences. Moreover, we employ a non-local block to capture global dependencies of temporal domain in an attention mechanism. Our model achieves improvements over the state-of-the-art methods on two large-scale datasets. |
Xin Yang*, Yuanbo Wang, Yaru Wang, Baocai Yin, Qiang Zhang, Xiaopeng Wei, and Hongbo Fu. Active Object Reconstruction Using a Guided View Planner. IJCAI 2018. Stockholm, Sweden, July 13 - 19, 2018. |
|
 |
Abstract: Inspired by the recent advance of image-based object reconstruction using deep learning, we present an active reconstruction model using a guided view planner. We aim to reconstruct a 3D model using images observed from a planned sequence of informative and discriminative views. But where are such informative and discriminative views around an object? To address this we propose a unified model for view planning and object reconstruction, which is utilized to learn a guided information acquisition model and to aggregate information from a sequence of images for reconstruction. Experiments show that our model (1) increases our reconstruction accuracy with an increasing number of views (2) and generally predicts a more informative sequence of views for object reconstruction compared to other alternative methods. [Paper] |
Jianhui Zhang, Yilan Chen*, Lei Li, Hongbo Fu, and Chiew-Lan Tai. Context-based sketch classification. Expressive 2018. Victoria, Canada, Aug. 17-19, 2018. |
|
 |
Abstract: We present a novel context-based sketch classification framework using relations extracted from scene images. Most of existing methods perform sketch classification by considering individually sketched objects and often fail to identify their correct categories, due to the highly abstract nature of sketches. For a sketched scene containing multiple objects, we propose to classify a sketched object by considering its surrounding context in the scene, which provides vital cues for alleviating its recognition ambiguity. We learn such context knowledge from a database of scene images by summarizing the inter-object relations therein, such as co-occurrence, relative positions and sizes. We show that the context information can be used for both incremental sketch classification and sketch co-classification. Our method outperforms a state-of-the-art single-object classification method, evaluated on a new dataset of sketched scenes. |
Yilan Chen*, Hongbo Fu, and Kin-Chung Au. A multi-level sketch-based interface for decorative pattern exploration.SIGGRAPH Asia 2016 Technical Briefs. Macao, Dec. 5-8, 2016. |
|
 |
Abstract: Despite the extensive usage of decorative patterns in art and design, there is a lack of intuitive ways to find a certain type of patterns. In this paper, we present a multi-level sketch-based interface that incorporates low-level geometrical features and high-level structural features, namely reflection, rotation, and translation symmetries, to support decorative pattern exploration at different levels of detail. Four brush tools are designed for users to specify any combination of such features and compose a hybrid search query. The results of a pilot study show that users are able to perform pattern retrieval tasks using our system easily and effectively. [Paper, Video, Project Page] |
Lei Li*, Zhe Huang*, Changqing Zou*, Chiew-Lan Tai, Rynson Lau, Hao Zhang, Ping Tan, and Hongbo Fu. Model-driven sketch reconstruction with structure-oriented retrieval. SIGGRAPH Asia 2016 Technical Briefs. Macao, Dec. 5-8, 2016. |
|
 |
Abstract: We propose an interactive system that aims at lifting a 2D sketch into a 3D sketch with the help of existing models in shape collections. The key idea is to exploit part structure for shape retrieval and sketch reconstruction. We adopt sketch-based shape retrieval and develop a novel matching algorithm which considers structure in addition to traditional shape features. From a list of retrieved models, users select one to serve as a 3D proxy, providing abstract 3D information. Then our reconstruction method transforms the sketch into 3D geometry by back-projection, followed by an optimization procedure based on the Laplacian mesh deformation framework. Preliminary evaluations show that our retrieval algorithm is more effective than a state-of-the-art method and users can create interesting 3D forms of sketches without precise drawing skills. |
Pui Chung Wong*, Hongbo Fu, and Kening Zhu. Back-Mirror: back-of-device one-handed interaction on smartphones. SIGGRAPH Asia 2016 Symposium on Mobile Graphics and Interactive Applications. Presentation and Demonstrations. Macao, Dec. 5-8, 2016. (Best Demo Honorable Mention) |
|
 |
Abstract: We present Back-Mirror, a low-cost camera-based approach for widening the interaction space on the back surface of a smartphone by using mirror reflection. Back-Mirror consists of two main parts: a smartphone accessory with a mirror that can reflect the back surface to the rear-facing camera of the phone, and a computer-vision algorithm for gesture recognition based on the visual pattern on the back surface. Our approach captures the finger position on the back surface, and tracks finger movement with higher resolution than the previous methods. We further designed a set of intuitive gestures that can be recognized by Back-Mirror, including swiping up, down, left and right, tapping left, middle, right, and holding gestures. Furthermore, we created applications of Back-of-device, such as game, media player, photo gallery, and unlock mechanism, allowing users to experience the use of Back-Mirror gestures in the real-life scenarios. [Paper, Video, Project Page] |
Qingkun Su*, Kin-Chung Au, Pengfei Xu, Hongbo Fu, and Chiew-Lan Tai. 2D-Dragger: Unified Touch-based Target Acquisition with Constant Effective Width. Mobile HCI 2016. Florence, September 6-9, 2016. |
|
 |
Abstract: In this work we introduce 2D-Dragger, a unified touch-based target acquisition technique that enables easy access to small targets in dense regions or distant targets on screens of various sizes. The effective width of a target is constant with our tool, allowing a fixed scale of finger movement for capturing a new target. Our tool is thus insensitive to the distribution and size of the selectable targets, and consistently works well for screens of different sizes, from mobile to wall-sized screens. Our user studies show that overall 2D-Dragger performs the best compared to the state-of-the-art techniques for selecting both near and distant targets of various sizes in different densities. |
Quoc Huy Phan*, Jingwan Lu, Paul Asente, Antoni B. Chan, and Hongbo Fu. Patternista: Learning element style compatibility and spatial composition for ring-based layout decoration. Expressive 2016. Lisbon, May 7-9, 2016. |
|
 |
Abstract: Creating aesthetically pleasing decorations for daily objects is a task that requires deep understanding of multiple aspects of object decoration, including color, composition and element compatibility. A designer needs a unique aesthetic style to create artworks that stand out. Although specific subproblems have been studied before, the overall problem of design recommendation and synthesis is still relatively unexplored. In this paper, we propose a flexible data-driven framework to jointly consider two aspects of this design problem: style compatibility and spatial composition. We introduce a ring-based layout model capable of capturing decorative compositions for objects like plates, vases and pots. Our layout representation allows the use of the hidden Markov models (HMM’s) technique to make intelligent design suggestions for each region of a target object in a sequential fashion. We conducted both quantitative and qualitative experiments to evaluate the framework and obtained favorable results. [Paper] |
Quoc Huy Phan*, Hongbo Fu, and Antoni B. Chan. Look closely: Learning exemplar patches for recognizing textiles from product images. ACCV 2014. Singapore, Nov 1-5, 2014. |
|
 |
Abstract: The resolution of product images is becoming higher dues to the rapid development of digital cameras and the Internet. Higher resolution images expose novel feature relationships that did not exist before. For instance, from a large image of a garment, one can observe the overall shape, the wrinkles, and the micro-level details such as sewing lines and weaving patterns. The key idea of our work is to combine features obtained at such largely different scales to improve textile recognition performance. Specifically, we develop a robust semi-supervised model that exploits both micro textures and macro deformable shapes to select representative patches from product images. The selected patches are then used as inputs to conventional texture recognition methods to perform texture recognition. We show that, by learning from human-provided image regions, the method can suggest more discriminative regions that lead to higher categorization rates (+5-7%). We also show that our patch selection method significantly improves the performance of conventional texture recognition methods that usually rely on dense sampling. Our dataset of labeled textile images will be released for further investigation in this emerging field. [Paper] |
| Chun Kit Tsui*, Chi Hei Law*, and Hongbo Fu. One-man Orchestra: conducting smartphone orchestra. SIGGRAPH Asia 2014, Emerging Technologoeis. Shenzhen, December, 2014. Best Demo Award | |
 |
Abstract: This work presents a new platform for performing one-man orchestra. The conductor is the only human involved, who uses traditional bimanual conducting gestures to interactively direct the performance of smartphones instead of human performers in a real-world orchestra. Each smartphone acts as a virtual performer who plays a certain music instrument like piano and violin. Our work not only allows ordinary people to experience music conducting but also provides a training platform so that students can practice music conducting with a unique listening experience. |
Jingbo Liu, Hongbo Fu, and Chiew-Lan Tai. Dynamic sketching: simulating the process of observational drawing. CAe '14: Proceedings of the Workshop on Computational Aesthetics. Vancouver, August 2014. |
|
 |
Abstract: The creation process of a drawing provides a vivid visual progression, allowing the audience to better comprehend the drawing. It also enables numerous stroke-based rendering techniques. In this work we tackle the problem of simulating the process of observational drawing, that is, how people draw lines when sketching a given 3D model. We present a multi-phase drawing framework and the concept of sketching entropy, which provides a unified way to model stroke selection and ordering, both within and across phases. We demonstrate the proposed ideas for the sketching of organic objects and show a visually plausible simulation of their dynamic sketching process. |
| Hongbo Fu, Xiaoguang Han*, and Phan Quoc Huy*. Data-driven suggestions for portrait posing. ACM SIGGRAPH Asia 2013, Technical Briefs, Hong Kong, November, 2013. Hongbo Fu, Xiaoguang Han*, and Phan Quoc Huy*. Data-driven suggestions for portrait posing. ACM SIGGRAPH Asia 2013, Emerging Technologies, Hong Kong, November, 2013. Best Demo Award. One of the four program highlights among all the accepted works. |
|
 |
Abstract: This work introduces an easy-to-use creativity support tool for portrait posing, which is an important but challenging problem in portrait photography. While it is well known that a collection of sample poses is a source of inspiration, manual browsing is currently the only option to identify a desired pose from a possibly large collection of poses. With our tool, a photographer is able to easily retrieve desired reference poses as guidance or stimulate creativity. We show how our data-driven suggestions can be used to either refine the current pose of a subject or explore new poses. Our pilot study indicates that unskilled photographers find our data-driven suggestions easy to use and useful, though the role of our suggestions in improving aesthetic quality or pose diversity still needs more investigation. Our work takes the first step of using consumer-level depth sensors towards more intelligent cameras for computational photography. |
Wing Ho Andy Li*and Hongbo Fu. BezelCursor: Bezel-initiated cursor for one-handed target acquisition on mobile touch screens. SIGGRAPH Asia 2013, Symposium on Mobile Graphics and Interactive Applications (Demonstrations). Hong Kong, November, 2013. |
|
|
Abstract: We present BezelCursor, a novel one-handed thumb interaction technique for target acquisition on mobile touch screens of various sizes. Our technique combines bezel-initiated interaction and gestural pointing to solve the problem of limited screen accessibility afforded by the thumb. With a fixed, comfortable grip of a mobile touch device, a user may employ our tool to easily and quickly access a target located anywhere on the screen, using a single fluid action. Unlike the existing technologies, our technique requires no explicit mode switching to invoke and can be smoothly used together with commonly adopted interaction styles such as direct touch and dragging. A user study shows that the performance of our technique is comparable to or even better than that of the state-of-the-art techniques, which, however, suffer from various problems such as explicit mode switching, finger occlusion and/or limited accessibility.. |
Lu Chen, Hongbo Fu, Wing Ho Andy Li*, and Chiew-Lan Tai. Scalable maps of random dots for middle-scale locative games. IEEE Virtual Reality 2013, Orlando, Florida, USA, March, 2013. |
|
 |
Abstract: In this work we present a new scalable map for middle-scale locative games. Our map is built upon the recent development of fiducial markers, specifically, the random dot markers. We propose a simple solution, i.e., using a grid of compound markers, to address the scalability problem. Our highly scalable approach is able to generate a middle-scale map on which multiple players can stand and position themselves via mobile cameras in real time. We show how a classic computer game can be effectively adapted to our middle-scale gaming platform. |
Wing Ho Andy Li*and Hongbo Fu. Augmented reflection of reality. SIGGRAPH 2012 Emerging Techologies, Los Angeles, USA, August, 2012. |
|
 |
Abstract: Unlike existing augmented-reality techniques, which typically augment the real world surrounding a user with virtual objects and visualize those effects using various see-through displays, this system focuses on augmenting the user's full body. A half-silvered mirror combines the user's reflection with synthetic data to provide a mixed world. With a live and direct view of the user and the surrounding environment, the system allows the user to intuitively control virtual objects (for example, virtual drums) via the augmented reflection. |
Bin Bao*and Hongbo Fu. Vectorizing line drawings with near-constant line width. IEEE Internationl Conference on Image Processing (ICIP 2012), Orlando, Florida, USA, September-October, 2012. |
|
 |
Abstract: Many line drawing images are composed of lines with near-constant width. Such line width information has seldom been used in the vectorization process. In this work, we show that by enforcing the nearconstant line width constraint, we are able to produce visually more pleasing vectorization results. To this end, we develop a tracingbased approach, allowing dynamic validation of the line width constraint. The key here is to derive correct tracing directions, which are determined based on an automatically estimated orientation field, shape smoothness and the near-constant line width assumption. We have examined our algorithm on a variety of line drawing images with different shape and topology complexity. We show that our solution outperforms the state-of-the-art vectorization software systems including WinTopo and Adobe Illustrator, especially at regions where multiple lines meet and thus are difficult to locally distinguish from each other. [Paper] |
Wei-Lwun Lu, James J. Little, Alla Sheffer, and Hongbo Fu. Deforestation: Extracting 3D bare-earth surface from airborne LiDAR data. The Fifth Canadian Conference on Computer and Robot Vision (CRV 2008), pages 203-210, Windsor, Canada, May 2008. |
|
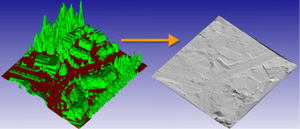 |
Abstract: Bare-earth identification selects points from a LiDAR point cloud so that they can be interpolated to form a representation of the ground surface from which structures, vegetation, and other cover have been removed. We triangulate the point cloud and segment the triangles into flat and steep triangles using a Discriminative Random Field (DRF) that uses a data-dependent label smoothness term.Regions are classified into ground and non-ground based on steepness in the regions and ground points are selected as points on ground triangles. Various post-processing steps are used to further identify flat regions as rooftops and treetops, and eliminate isolated features that affect the surface interpolation.The performance of our algorithm is evaluated in its effectiveness at labeling ground points and, more importantly, at determining the extracted bare-earth surface. Extensive comparison shows the effectiveness of the strategy at selecting ground points leading to good fit in the triangulated mesh derived from the ground points. [Paper] |
|
Hongbo
Fu, Yichen Wei, Chiew-Lan
Tai, and Long Quan. Sketching
hairstyles, EUROGRAPHICS Workshop on Sketch-Based
Interfaces and Modeling
(SBIM 2007), pages 31-36, UC Riverside, USA, July 2008. [citation] |
|
 |
Abstract:
This paper presents an intuitive sketching interface for interactive
hairstyle design, made possible by an efficient numerical updating
scheme. The user portrays the global shape of a desired hairstyle
through a few 3D style curves that are manipulated by interactively
sketching freeform strokes. Our approach is based on a vector field
representation that solves a sparse linear system with the style curves
acting as boundary constraints. The key observation is that the
specific sparseness pattern of the linear system enables an efficient
incremental numerical updating scheme. This gives rise to a sketching
interface that provides interactive visual feedback to the user.
Interesting hairstyles can be easily created in minutes. [Paper] |
| Xiaohuang Huang, Hongbo Fu, Oscar Kin-Chung Au, and Chiew-Lan Tai. Optimal boundaries for Poisson mesh merging, ACM Solid and Physical Modeling Symposium 2007 (SPM 2007), pages 35-40, Beijing, China, June 2007. (Acceptance rate: 26.6%) [citation] | |
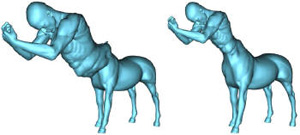 |
Abstract:
Existing Poisson mesh editing techniques mainly focus on designing
schemes to propagate deformation from a given boundary condition to a
region of interest. Although solving the Poisson system in the
least-squares sense distributes the distortion errors over the entire
region of interest, large deformation in the boundary condition might
still lead to severely distorted results. We propose to optimize the
boundary condition (the merging boundary) for Poisson mesh merging. The
user needs only to casually mark a source region and a target region.
Our algorithm automatically searches for an optimal boundary condition
within the marked regions such that the change of the found boundary
during merging is minimal in terms of similarity transformation.
Experimental results demonstrate that our merging tool is easy to use
and produces visually better merging results than unoptimized
techniques. [Paper] |
|
Xiangye
Xiao, Qiong Luo, Dan
Hong, and Hongbo Fu. Slicing*-tree
based web page transformation for small displays.
ACM Fourteenth Conference on Information and Knowledge Management (CIKM
2005), Bremen, Germany, 2005. (Journal version appears in ACM Transactions on the Web) [citation] |
|
|
Hongbo
Fu, Chiew-Lan Tai, and Oscar
Kin-Chung Au. Morphing with Laplacian
coordinates and spatial-temporal texture, In
Proceedings of Pacific Graphics 2005 (PG 2005), pages
100-102, Macao, China, October 2005. (Acceptance rate: 35.5%) [citation] |
|
 |
Abstract:
Given 2D or 3D shapes, the objective of morphing is to create a
sequence of gradually changed shapes and to keep individual shapes as
visually pleasing as possible. In this paper, we present a morphing
technique for 2D planar curves (open or closed) by coherently
interpolating the source and target Laplacian coordinates. Although the
Laplacian coordinates capture the geometric features of a shape, they
are not rotation-invariant. By applying as-rigid-as-possible
transformations with rotation coherence constraints to the Laplacian
coordinates, we make the intermediate morphing shapes highly appealing.
Our method successfully avoids local self-intersections. We also
propose to interpolate the textures within simple closed curves using a
spatial-temporal structure. In existing texture morphing techniques,
textures are encoded by either skeleton structures or triangulations.
Therefore, the morphing results depend on the quality of these skeleton
structures or triangulations. Given two simple closed curves and their
interpolated shapes, our method automatically finds a one-to-one
mapping between the source and target textures without any skeleton or
triangulation and guarantees that neighboring pixels morph coherently. [Paper] |
|
Oscar
Kin-Chung Au, Chiew-Lan Tai, Hongbo
Fu, and Ligang Liu. Mesh
editing with curvature flow Laplacian, Symposium on Geometry Processing 2005
(SGP 2005),
Vienna, Austria, July, 2005 (Poster). [citation]
|
|
 |
Introduction: Differential coordinates are essentially vectors encoded in the global coordinate system. Since the local features on a mesh are deformed and rotated during editing, the differential coordinates must somehow be transformed to match the desired new orientations, otherwise distortion like shearing and stretching will occur. This transformation problem is basically a chicken-and-egg problem: the reconstruction of the deformed surface requires properly oriented differential coordinates, while the reorientation of these coordinates depend on the unknown deformed mesh. We present an iterative Laplacian-based editing framework to solve this transformation problem. The only user input required are the positions of the handles, not their local frames. Thus our system supports simple point handle editing. Our iterative updating process finds the best orientations of local features, including the orientations at the point handles. |
|
Hongbo
Fu, Chiew-Lan Tai, and Hongxin
Zhang. Topology-free
cut-and-paste editing over meshes, Geometric Modeling and Processing 2004
(GMP 2004),
pages 173 – 182, Beijing, China, April, 2004. (Acceptance rate:
23.3%) [citation]
|
|
 |
Abstract:
Existing cut-and-paste editing methods over meshes are inapplicable to
regions with non-zero genus. To overcome this drawback, we propose a
novel method in this paper. Firstly, a base surface passing through the
boundary vertices of the selected region is constructed using the
boundary triangulation technique. Considering the connectivity between
the neighboring vertices, a new detail encoding technique is then
presented based on surface parameterization. Finally, the detail
representation is transferred onto the target surface via the base
surface. This strategy of creating a base surface as a detail carrier
allows us to paste features of non-zero genus onto the target surface.
By taking the physical relationship of adjacent vertices into account,
our detail encoding method produces more natural and less distorted
results. Therefore, our elegant method not only can eliminate the
dependence on the topology of the selected feature, but also reduces
the distortion effectively during pasting. [Paper] |
Book & Thesis
|
Hongbo
Fu. Advanced
programming in Delphi 6.0, Publishing House of Electronics
Industry, March 2002, ISBN 7-900084-62-2
(in Chinese). Buy this book at dearbook. |
|||
 |
Brief
introduction: This book presents the essence of Delphi
programming through a variety of advanced examples. The examples focus
on the development of multimedia and Internet applications, for
example, OpenGL, Indy components, XML, Web Broker and WebSnap
techniques. |
||
| Hongbo Fu. Differential methods for intuitive 3D shape modeling, Ph.D. Thesis, 20 July 2007. | |||
|
|||
| Hongbo Fu. Magnetocardiography signal denoising techniques. Undergraduate Thesis, July 2002. | |||

Technical Report
Wei-Lwun Lu, Kevin. P. Murphy, James J. Little, Alla Sheffer, and Hongbo Fu.Coupled CRFs for estimating the underlying ground surface from airborne LiDAR data, UBC CS TR-2008-05, May 2008. |
|
| Hongbo Fu. Differential methods for intuitive 3D shape modeling, PhD Thesis Proposal, 21 May 2007. | |
Oscar
Kin-Chung Au, Chiew-Lan Tai, Hongbo
Fu, and Ligang Liu. Mesh
editing with curvature flow Laplacian operator,
Technical report, HKUST-CS05-10, July 2005. [citation] |
|
|
Abstract:
Recently, differential information as local intrinsic feature
descriptors has been used for mesh editing. Given certain user input as
constraints, a deformed mesh is reconstructed by minimizing the changes
in the differential information. Since the differential information is
encoded in the global coordinate system, it must somehow be transformed
to fit the orientation of details in the deformed surface, otherwise
distortion will appear. We observe that visually desired deformed
meshes should preserve both local parameterization and geometry
details. To find suitable representations for these two types of
information, we exploit certain properties of the curvature flow
Laplacian operator. Specifically, we consider the coefficients of
Laplacian operator as the parametrization information and the
magnitudes of the Laplacian coordinates as the geometry information.
Both sets of information are non-directional and non-linearly dependent
on the vertex positions. Thus, we propose a new editing framework that
iteratively updates both the vertex positions and the Laplacian
coordinates to reduce distortion in parametrization and geometry. Our
method can produce visually pleasing deformation with simple user
interaction, requiring only the handle positions, not the local frames
at the handles. In addition, since the magnitudes of the Laplacian
coordinates approximate the integrated mean curvatures, our framework
is useful for modifying mesh geometry via updating the curvature field.
We demonstrate this use in spherical parameterization and non-shrinking
smoothing. |
Hongbo
Fu, Chiew-Lan Tai. Mesh
editing with affine-invariant Laplacian coordinates,
Technical report, HKUST-CS05-01, January 2005. |
|
 |
Abstract:
Differential coordinates as an intrinsic surface representation capture
geometric details of surface. However, differential coordinates alone
cannot achieve desirable editing results, because they are not affine
invariant. In this paper, we present a novel method that makes the
Laplacian coordinates completely affine-invariant during editing. For
each vertex of a surface to be edited, we compute the Laplacian
coordinate and implicitly define a local affine transformation that is
dependent on the unknown edited vertices. During editing, both the
resulting surface and the implicit local affine transformations are
solved simultaneously through a constrained optimization. The
underlying mathematics of our method is a set of linear Partial
Differential Equations (PDEs) with a generalized boundary condition.
The main computation involved comes from factorizing the resulting
sparse system of linear equations, which is performed only once. After
that, back substitutions are executed to interactively respond to user
manipulations. We propose a new editing technique, called
pose-independent merging, to demonstrate the advantages of the
affine-invariant Laplacian coordinates. In the the same framework,
large-scale mesh deformation and pose-dependent mesh merging are also
presented. |
| Hongbo Fu. A survey of editing techniques on surface models and point-based models, PhD Qualifying Examination, 19 December 2003. | |